
Introduction
Big data is used by organisations for the sole purpose of analytics. However, before companies can set out to extract insights and valuable information from big data, they must have the knowledge of data sources. Data, as we know, is massive and exists in various forms. Therefore we can say that dealing with big data in the best possible manner is becoming the main area of interest for businesses, scientists and individuals. When processing large amounts of data, there is usually a delay between the point when data is collected and its availability in reports and dashboards. In this article we’ll try to explore data processing architectures that serve as the backbone of various enterprise applications known as Lambda Architecture.
Lambda Architecture
The basis of the Lambda architecture is to compute arbitrary functions on distributed datasets in real-time and to combine batch and real-time processing capabilities to balance data latency throughput, and fault tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data.
While we mention data processing we basically use this term to represent high throughput, low latency and aiming for near-real-time applications. Which also would allow the developers to define delta rules in the form of code logic or NLP in event-based data processing models to achieve robustness, automation and improve the data quality.
In this architecture, one can query both fresh and historical data. To gain insight into the historical data movements. The architecture has also solved the problem of computation of arbitrary functions. In general, a problem can be segregated into three layers:
- Batch Layer
- Speed Layer
- Serving Layer
Basic diagram of Lambda Architecture Model
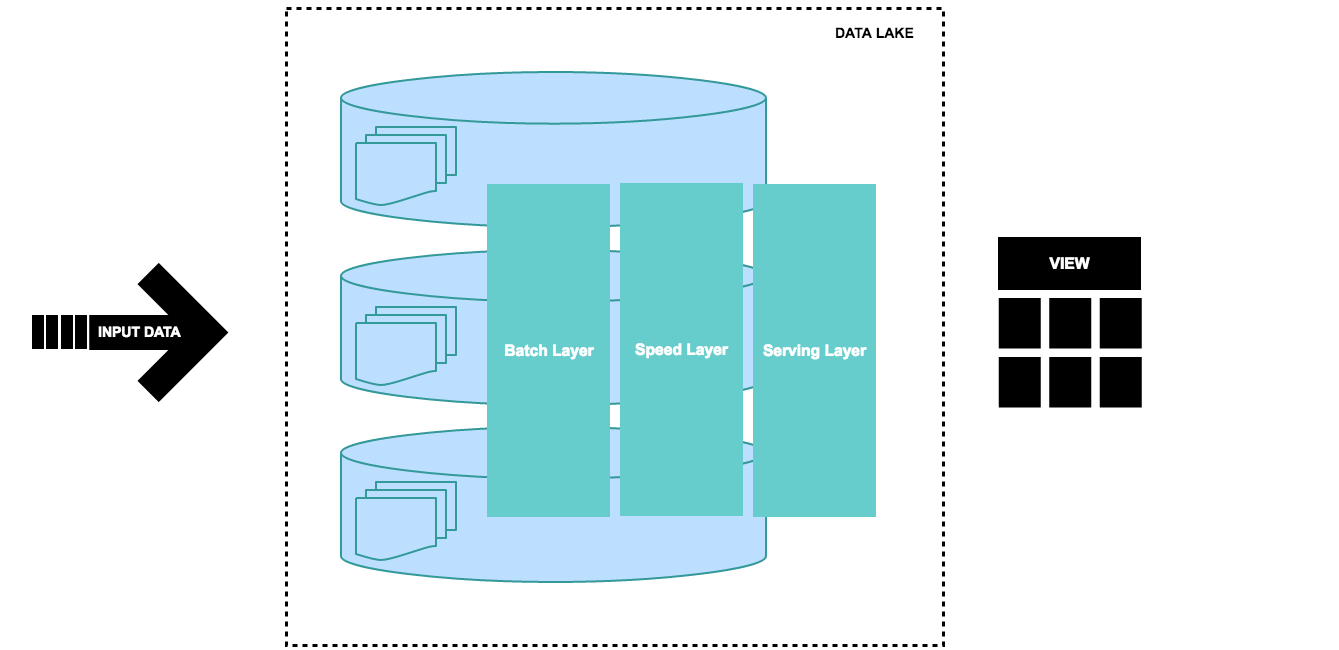
-
Batch Layer
The batch layer is mainly responsible for two tasks. The first is to store the constantly growing master data in a data lake, which is in this case a Hadoop distributed file system or databases such as in memory databases or NoSQL based storages. The second task is to precompute batch views for this distributed data by using the Spark or MapReduce processing paradigm. Those batch views can be used to answer incoming queries with low read latency.
-
Speed Layer
The speed layer, we are processing the streaming data using Kafka/Kinesis with Spark streaming and two main tasks are done in this layer: first, the stream data is appended into data lake for later batch processing; Second, Speed layer provides the outputs on the basis enrichment process and supports the serving layer to reduce the latency in responding the queries. As obvious from its name the speed layer has low latency because it deals with the real time data.
-
Serving Layer
The serving layer, merged query is aimed at joining and analyzing the data from both the batch view from the batch layer and the incremental stream view from the speed layer. This way the serving layer can provide the real-time computation results over all data.
Conclusion
The Lambda architecture described in this provides the building blocks of a unified architectural pattern that unifies stream (real-time) and batch processing within a single code base. Through the use of Spark Streaming and Spark SQL APIs, you implement your business logic function once, and then reuse the code in a batch ETL process as well as for real-time streaming processes. In this way, you can quickly implement a real-time layer to complement the batch-processing one. In the long term, this architecture will reduce your maintenance overhead. It will also reduce the risk for errors resulting from duplicate code bases.
Comments