
Kafka
Kafka is everywhere these days. With the development of Microservices, Big Data and distributed computing. Kafka has become a regular occurrence in architecture’s of every product. This is all well and great, but stripped down to its core, Kafka is a distributed, horizontally scalable, fault-tolerant commit log.
Lets proceed with Kafka storage internals:
Azuming you have some basic understanding about Kafka. we can start with Partition and Topic first.
Kafka Topic
Kafka Topic caters the entire purpose. Kafka topics are really just a named feed or category of messages. One way to think of it would be to consider a mailbox. It’s an addressable, referenceable collection point for messages that producers send messages to and consumers retrieve messages from.
Topic is merely a logical grouping of several partitions.
In Kafka, a topic is a logical entity, something that virtually spans across the entire cluster of brokers. Producers and consumers alike don’t really know or care about where and how the messages are kept. They just care about the topic to work with.
Topic is from a logical viewpoint
- Topics can span an entire cluster of brokers for the benefit of scalability and fault tolerance.
- With the abstraction of a topic, a producer simply needs to publish messages to that topic.
- Similarly, consumers simply want to consume from a topic, regardless of where it is.
What’s happening within any given topic
- When a producer sends a message to a Kafka topic, the messages are appended to a time‑ordered sequential stream.
- Each message represents an event, or fact, that from the perspective of the producer and make available to potential consumers.
- These events are immutable. Once they are received into a topic, they cannot be changed.
Kafka Partitions
The topic, as a logical concept, is represented by one or more physical log files called partitions. Partitions are the units of storage in Kafka for messages.
The number of partitions per topic is entirely configurable. The partition itself is central to how Apache Kafka achieves scalability, greater levels of fault tolerance and higher levels of throughput.
Each topic has to have a single partition because that partition, as I mentioned, is the physical representation of the topic as a commit log stored on one or more brokers. The log maintained on the broker’s file system in the directory tmp/kafka‑logs. For the topic subfolder created called my_topic‑0, which contained the log for that single partition.
Resources standpoint
- Partition resides on broker. which is limited by a finite amount of computational resources, such as CPU, memory, disk space, and network.
- Considering each partition you have must fit on one machine. You cannot split a single partition across multiple machines. Therefore, if you only have one partition for a large and growing topic, you will be limited by the one broker node’s ability to capture and retain messages.
- In Kafka, that means you’ll need more brokers in the cluster and topics that can leverage those brokers by partitioning into multiple partitions.
Distribution standpoint
-
For example, when a command to create a topic with three partitions has issued, it is handled by ZooKeeper, who is maintaining metadata regarding the cluster.
-
ZooKeeper is going to look at the available brokers and decide which brokers will be made the responsible leaders for managing the partitions within a topic.
-
When that assignment is made, each unique Kafka broker will create a log for the newly assigned partition.
-
Additionally, as partition assignments are broadcast, each individual broker maintains a subset of the metadata that ZooKeeper does, particularly the mapping of what partitions are being managed by what brokers in the cluster. This enables any individual broker to direct a producer client to the appropriate broker for producing messages to a specific partition.
Parallelism standpoint
Number of partition is a architectural decision, the number of Kafka partitions will have its tradeoffs. therefore, a right balance needs to be found based on use case needs and resource availability.
if you have more partitions, the more entry ZooKeeper has to make to keep track of them. And since ZooKeeper works on this registry in memory, the resources on ZooKeeper can become constrained.
if you have less partitions, you cannot effectively scale out the application to consume the partitions because Kafka allows only one consumer per topic partition.
let’s understand these concepts better by working with Kafka.
lets start by creating a topic in Kafka with three partitions. The command looks like this for a local Kafka setup on windows.
kafka-topics.bat --create --topic my_topic --partitions 3 --replication-factor 1 --zookeeper localhost:2181
Go to the Kafka log directory and you see three directories are created.
my_topic-0
|-- 00000000000000000000.index
|-- 00000000000000000000.log
|-- 00000000000000000000.timeindex
`-- leader-epoch-checkpoint
my_topic-1
|-- 00000000000000000000.index
|-- 00000000000000000000.log
|-- 00000000000000000000.timeindex
`-- leader-epoch-checkpoint
my_topic-2
|-- 00000000000000000000.index
|-- 00000000000000000000.log
|-- 00000000000000000000.timeindex
`-- leader-epoch-checkpoint
Three directories created because we’ve given three partitions for our topic, which means that each partition gets a directory on the file system. You see the index files combined are about 20M in size while the log file is completely empty. This is the same case with my_topic-1 and my_topic-2 folders.
- my_topic 197121 10M Jan 5 08:26 00000000000000000000.index
- my_topic 197121 0 Jan 5 08:26 00000000000000000000.log
- my_topic 197121 10M Jan 5 08:26 00000000000000000000.timeindex
- my_topic 197121 0 Jan 5 08:26 leader-epoch-checkpoint
if you send messages to Kafka, then Kafka arbitrarily picks the partition for the first message and then distributes the messages to partitions in a round robin fashion.
Each new message in the partition gets an Id also called as the Offset. So, the first message is at ‘offset’ 0, the second message is at offset 1 and so on. These offset Id’s are always incremented from the previous value.
Segments:
Partition might be the standard unit of storage in Kafka, but it is not the lowest level of abstraction provided. Each partition is sub-divided into segments.
A segment is simply a collection of messages of a partition. Instead of storing all the messages of a partition in a single file (think of the log file analogy again), Kafka splits them into chunks called segments. The default value for segment size is a high value (1 GB)
The 00000000000000000000 in front of the log and the index files in each partition folder, is the name of our segment. Each segment file has segment.log ,segment.index and segment.timeindex files.
Kafka always writes the messages into these segment files under a partition. There is always an active segment to which Kafka writes to. Once the segment’s size limit is reached, a new segment file is created and that becomes the newly active segment.

Each segment file is created with the offset of the first message as its file name. So, In the above picture, segment 0 has messages from offset 0 to offset 2, segment 3 has messages from offset 3 to 5 and so on. Segment 6 which is the last segment is the active segment.
Use of Index file:
One of the common operations in Kafka is to read the message at a particular offset. For this, if it has to go to the log file to find the offset, it becomes an expensive task especially because the log file can grow to huge sizes (Default — 1G). This is where the .index file becomes useful. Index file stores the offsets and physical position of the message in the log file.
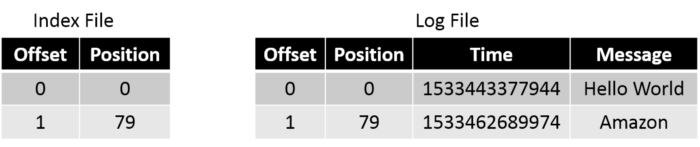
If you need to read the message at offset 1, you first search for it in the index file and figure out that the message is in position 79. Then you directly go to position 79 in the log file and start reading.
Parallelism with Partitions
Increasing the number of consumers won’t increase the parallelism (Kafka allows only one consumer per topic partition). You need to scale your partitions accordingly. To read data from a topic in parallel with two consumers, you create two partitions so that each consumer can read from its own partition. Also since partitions of a topic can be on different brokers, two consumers of a topic can read the data from two different brokers.
Conclusion
Kafka is a scalable, fault-tolerant, publish-subscribe messaging system that enables you to build distributed applications. We covered how Topic and Partitions work in Kafka.
Comments