
What is Late Data
The data is considered to be late when it arrives to the system after the end of its window. For instance let’s suppose we’ve a window storing items for event time included in 2020-02-02 10:00 - 2020-02-02 10:15 interval. Any item having the event time included in this interval but that comes to the system after the window computation is considered to be on late.
But, Why should we care?
In window aggregation Spark automatically takes cares of late data. Every aggregate window is like a bucket i.e. as soon as we receive data for a particular new time window, we automatically open up a bucket and start counting the number of records falling in that bucket. These buckets stay open for data which may even come 2 hours late and it will still update that old bucket and thus incrementing the count.
Structured Streaming can maintain the intermediate state for partial aggregates for a long period of time such that late data can update aggregates of old windows correctly.
Problems:
- The size of the state will continue to increase over time so number of window are increase to handling all the late events .
- Some of the late events may not have much business value after a while.
- Reading/Writing state for every micro batch slower the job execution.
Lets see in example what events are late events
Suppose we want to find the total number of product sell in every five minutes.
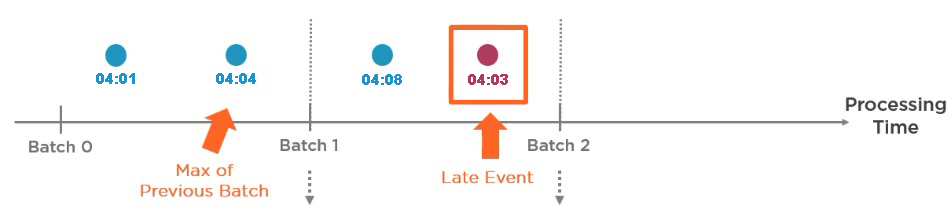
- First micro batch contains two events from 04:00 to 04:05.
- Second micro batch contains two events from 04:05 to 04:10 but one event is late event (in above diagram shown in red 04:03)
How spark know 04:03 is a late event : First of all, spark calculates, Max Time from previous batch , the max event time from previous is 04:04. then spark check if any up coming event is smaller than 04:04 is a late event.
The event is a late event. If it’s timestamp is smaller than the max timestamp from the previous batch.
How state cleanup happens
It is necessary for the system to bound the amount of intermediate in-memory state it accumulates. This means the system needs to know when an old aggregate can be dropped from the in-memory state because the application is not going to receive late data for that aggregate any more.
Spark introduced watermarking: Watermark is moving threshold of how late the data is expected to be and accordingly the engine can drop old state. You can define the watermark of a query by specifying the event time column and the threshold on how late the data is expected to be in terms of event time.
How Spark calculate the Watermarking:
val productDF = df.withWatermark("productTime", "10 minutes")
.groupBy(window($"productTime", "5 minutes"))
.count()
- Lets say the watermark value is 10 minutes.
- Next for every micro batch execution spark engine will first calculate the maximum time off previous batch (Assume that it is 04:30).
- Now spark will calculate the watermark. It’s a difference between maximum time and the watermark value (04:30 minus 10 minutes = 04:20) called the watermark, and this is now the acceptable delay.
- The events which are 04:20 to 04:30 are late events, but they are accepted and processed by spark.
- The events older than watermark with event time before 04:20 are considered too late and these events will be dropped by spark.
- Any windows which are older than watermark are also dropped from the state.
Let’s understand with example:
Suppose we want to find the total number of product sell in every 10 minutes with 8 minutes of watermark.

- Batch 1 have two events from 04:00 to 04:10.
- Batch 2 have three events from 04:10 to 04:20 and if you see in the above diagram Batch 2 table for watermark calculations 04:00 is the watermark threshold value.
- The first event is valid because the event is in the current window timestamp.
- The second event 04:04 is late event but it’s acceptable because the value is grater than the watermark value(04:00).
- The third event is valid because the event is in the current window timestamp.
- Batch 3 have three events from 04:20 to 04:30 and if you see in the above diagram Batch 3 table for watermark calculations 04:10 is the watermark threshold value.
- The first event is valid because the event is in the current window timestamp.
- The second event 04:12 is late event but it’s acceptable because the value is grater than the watermark value(04:10).
- The third event 04:06 is too late event and it’s not acceptable because the value is less than the watermark value (04:10).
How watermark works in different Output Modes
- Update Output Mode: If this query is run in Update output mode, the engine will keep updating counts of a window in the Result Table until the window is older than the watermark.
- Append Output Mode: The engine maintains intermediate counts for each window. However, the partial counts are not updated to the Result Table and not written to sink. The engine waits for “_ mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window
04:00 - 04:10is appended to the Result Table only after the watermark is updated to04:11. - Complete Output Mode: Complete mode requires all aggregate data to be preserved, and hence cannot use watermarking to drop intermediate state.
Comments