
Join Operation on Streaming
Structured Streaming supports joining a streaming DataFrame with a static DataFrame as well as another streaming DataFrame. The result of the streaming join is generated incrementally, similar to the results of streaming aggregations.
Joining Stream with Static data
In many of the cases, you won’t be working with stream of data only. Only many a times you are required to join the Streaming data with other static data sets.
val streamingDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "join_events")
.load()
val staticDF=spark.read
.option("header","true")
.option("inferSchema","true")
.csv("input_path")
val joinDF = streamingDF.join(staticDF,List("id"),"inner")
Note that stream-static joins are not stateful, so no state management is necessary.
Supported Join Types
- Inner Join : Inner join type is Supported and it’s not not Stateful
- Left Outer Join : Left Outer join type is supported when streaming DataFrame on left side of the join and it’s not Stateful.
- Right Outer Join : Right Outer join type is supported when streaming DataFrame on right side of the join and it’s not Stateful.
- Full Outer Join : Full Outer join type is not Supported.
Joining Stream with Stream
Spark added support for stream-stream joins, that is, you can join two streaming DataFrames. In which we can join multiple streams together.
val streamingDFTest1 = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "join_events_test1")
.load()
val streamingDFTest2 = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "join_events_test2")
.load()
val joinDF = streamingDFTest1.join(streamingDFTest2,List("column"),"inner")
Note that stream-stream joins are stateful, so state management is necessary.
Supported Join Types
- Inner Join : Inner join type is Supported and it’s not not Stateful
- Left Outer Join : Conditionally supported, must specify watermark on right + time constraints for correct results, optionally specify watermark on left for all state cleanup.
- Right Outer Join : Conditionally supported, must specify watermark on left + time constraints for correct results, optionally specify watermark on right for all state cleanup.
- Full Outer Join : Full Outer join type is not Supported.
why is this a Stateful operation?
Let’s assume an example in which we have some sensor events. sensor generates a start and then after sensor generates end event after the start events.
- So ideally, the end events should arrive and processed after the start events.
- This means the start events must be stored in the state to match the end events which will come in the future.
- Events can be delayed. start events can arrive after end events.
- This means end events must be stored in state, to match start events come in future.
The challenge of generating join results between two data streams is that, at any point of time, the view of the dataset is incomplete for both sides of the join making it much harder to find matches between inputs. Any row received from one input stream can match with any future, yet-to-be-received row from the other input stream. Hence, for both the input streams, we buffer past input as streaming state, so that we can match every future input with past input and accordingly generate joined results.
Lets understand state with Example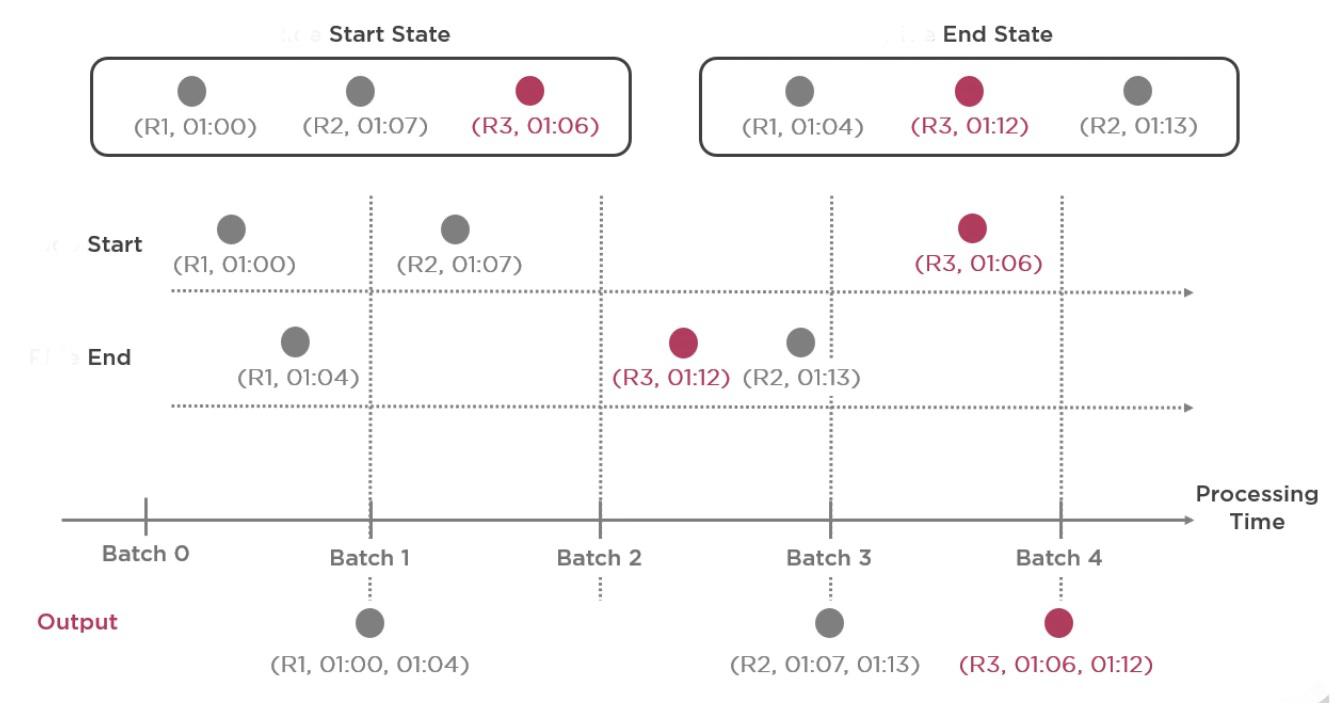
- Batch 1 we have two events one from start event and one from end event. both events are stored in start state and end state store and join generates output as (R1,01:00,01:04)
- Batch 2 have only one start event with id R2 but batch 2 don’t have any end event so join does not produce any output. Spark store the start event in start state store and expect the end event in future.
- Batch 3 have two end events with id R3, R2 and both the events are store in end state store but there is no start event. but spark find match for R2 from start state store and produce join output (R2,01:07,01:13).
- Batch 4 have one late start event R3 and stored in start state store. As spark maintaining the state automatically and gracefully handle the late data. After that join produce the output (R3,01:06,01:12).
Handling state in Stream-Stream join
As we know to join two streams together, the event from both the streams will be stored in the state store.
The challenge The size of the state will continue to increase infinitely with events from both the streams. This increases the micro batch processing time and can cause memory issues.
How to Limit the state
- Watermarking this is the maximum acceptable delay for an event to reach the processing engine. e.g. any start event that reaches 2 hours late is acceptable.
val streamingDFTest1 = spark.readStream .... val streamingDFTest2 = spark.readStream .... .... .... val watermarkDF1 = streamingDFTest1.withWatermark("eventTime","2 hours") val watermarkDF2 = streamingDFTest1.withWatermark("eventTime","2 hours") val joinDF = watermarkDF1.join(watermarkDF2,List("column"),"inner") -
Time Constraints is the range between generation off events at the source. This means what could be the maximum time between generation off to events. e.g. A sensor event can take up to 3 hours to complete the event.
```scala val streamingDFTest1 = spark.readStream ….
val streamingDFTest2 = spark.readStream .... .... .... val joinDF = streamingDFTest1.join(streamingDFTest2,"startID = endID AND endTime <= startTime + interval 3 hours") ```
Points to Remember
The outer NULL results will be generated with a delay that depends on the specified watermark delay and the time range condition. This is because the engine has to wait for that long to ensure there were no matches and there will be no more matches in future.
If any of the two input streams being joined does not receive data for a while, the outer (both cases, left or right) output may get delayed.
Comments