
Kafka Streams Partitions and Tasks
Kafka Streams uses the concepts of stream partitions and stream tasks as logical units of its parallelism model. There are close links between Kafka Streams and Kafka in the context of parallelism:
- First Kafka stream analyse the applications processor or topology (user defined kafka stream application) and then scaled it by breaking it into multiple stream tasks.
- Next Kafka Streams creates a fixed number of stream tasks based on the input stream partitions for the application.
- Next each task being assigned a list of partitions from the input streams (kafka topic).
The maximum parallelism at which your application may run is bounded by the maximum number of stream tasks, which itself is determined by maximum number of partitions of the input topic(s) the application is reading from. For example, if your input topic has 5 partitions, then you can run up to 5 applications instances. These instances will collaboratively process the topic’s data. If you run a larger number of app instances than partitions of the input topic, the “excess” app instances will launch but remain idle.
Breaking your topology down into sub-topologies and creates tasks
Let’s understand by one simple example mentioned below. we read from one topic, apply some transformations and aggregation and write to another topic. Behind the scene Kafka Streams will break the mentioned operators into tasks and starting execution.
The topology can be further broken down into sub-topologies. The idea of a sub-topology is that it can be run entirely independently from any other sub-topology.
streamBuilder
.mapValues(value -> value.toLowerCase())
.flatMapValues(value -> Arrays.asList(value.split("#")))
.selectKey((key, value) -> value)
.groupByKey()
.count()
.toStream()
.to("out_word");
In the example topology above we use the different operators like mapValues(), flatMapValues(), selectKey(), etc and create topology out of that. This topology can be broken up into two separate sub-topologies.

Describing your Kafka Streams application topology Kafka Streams makes it very simple to see how your Kafka Stream application has been broken down into sub-topologies. You simply need to describe your topology.
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [in_word])
--> KSTREAM-MAPVALUES-0000000001
Processor: KSTREAM-MAPVALUES-0000000001 (stores: [])
--> KSTREAM-FLATMAPVALUES-0000000002
<-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-FLATMAPVALUES-0000000002 (stores: [])
--> KSTREAM-KEY-SELECT-0000000003
<-- KSTREAM-MAPVALUES-0000000001
Processor: KSTREAM-KEY-SELECT-0000000003 (stores: [])
--> KSTREAM-FILTER-0000000007
<-- KSTREAM-FLATMAPVALUES-0000000002
Processor: KSTREAM-FILTER-0000000007 (stores: [])
--> KSTREAM-SINK-0000000006
<-- KSTREAM-KEY-SELECT-0000000003
Sink: KSTREAM-SINK-0000000006 (topic: KSTREAM-AGGREGATE-STATE-STORE-0000000004-repartition)
<-- KSTREAM-FILTER-0000000007
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000008 (topics: [KSTREAM-AGGREGATE-STATE-STORE-0000000004-repartition])
--> KSTREAM-AGGREGATE-0000000005
Processor: KSTREAM-AGGREGATE-0000000005 (stores: [KSTREAM-AGGREGATE-STATE-STORE-0000000004])
--> KTABLE-TOSTREAM-0000000009
<-- KSTREAM-SOURCE-0000000008
Processor: KTABLE-TOSTREAM-0000000009 (stores: [])
--> KSTREAM-SINK-0000000010
<-- KSTREAM-AGGREGATE-0000000005
Sink: KSTREAM-SINK-0000000010 (topic: out_word)
<-- KTABLE-TOSTREAM-0000000009
Generating tasks from sub-topologies
Generating sub-topologies from your overall topology is a static process that is performed at the time your topology is built and prior to connecting with Kafka. When your Kafka Streams application is started, the streams API will fetch metadata on each of the source topics from Kafka to determine how to break each sub-topology down into tasks. A task is the smallest unit of work that can be performed in parallel in a Kafka Streams application.
Let’s assume we have below example and input topic have two partitions and see how task are created:
streamBuilder
.mapValues(value -> value.toLowerCase())
.flatMapValues(value -> Arrays.asList(value.split("#")))
.selectKey((key, value) -> value)
.groupByKey()
.count()
.toStream()
.to("out_word");
Task allocation :
- First kafka stream break the topology into sub-topologies. In above example two sub-topologies are created. stream API break the first sub topology after selectKey() operation because it internally create repartitioning. second sub topology read from repartitioning topic and do aggregation like count().
- Next Stream API fetch metadata and check number of partitions for each source topic and create one task per partition.
- Next Stream API create 4 tasks because first sub topology has two partitions and second sub topology has also two partitions.
Task names are of the form:
<sub-topology-number>_<partition_number>
In the above example, for sub-topology 1 and sub-topology 2, each source topic has 2 partitions. These topics are assigned to task like [1_0, 1_1],[2_0,2_1].
Assigning tasks to running Thread
A StreamThread is basically a JVM thread. Task are assigned to StreamsThread for execution. In the current implementation, a StreamThread basically loops over all tasks and processes some amount of input data for each task. In between, the StreamThread (that is using a KafkaConsumer) polls the broker for new data for all its assigned tasks.
A StreamThread is an actual Java thread with its own unique Kafka consumer and producer instances. Each StreamThread is assigned tasks to perform. A Kafka Streams application’s capacity is defined by the total number of StreamThread instances available over all running instances of the application.
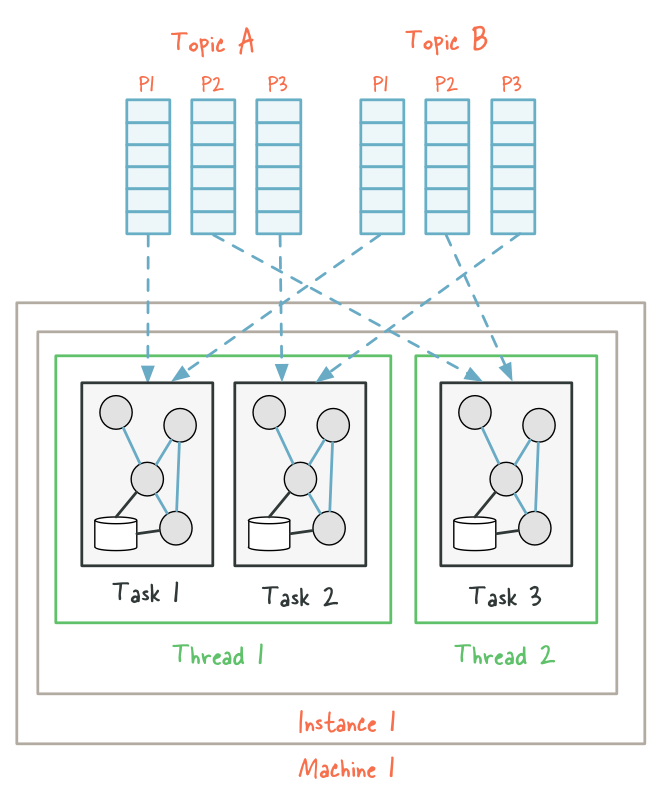
Threading Model
Kafka Streams allows the user to configure the number of threads that the library can use to parallelize processing within an application instance. Each thread can execute one or more stream tasks with their processor topologies independently.
To understand the parallelism model that Kafka Streams offers, let’s walk through an example.
Assume a Kafka Streams application that consumes from two topics, A and B, with each having 3 partitions. If we now start the application on a single machine with the number of threads configured to 2. Kafka Streams will break this topology into three tasks because the maximum number of partitions across the input topics A and B is 3, and then distribute the six input topic partitions evenly across these three tasks. Finally, these three tasks will be spread evenly – to the extent this is possible – across the two available threads, which in this example means that the first thread will run 2 tasks (consuming from 4 partitions) and the second thread will run 1 task (consuming from 2 partitions).
Comments