
Azure Synapse
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated resources—at scale. Azure Synapse brings these worlds together with a unified experience to ingest, explore, prepare, manage and serve data for immediate BI and machine learning needs.
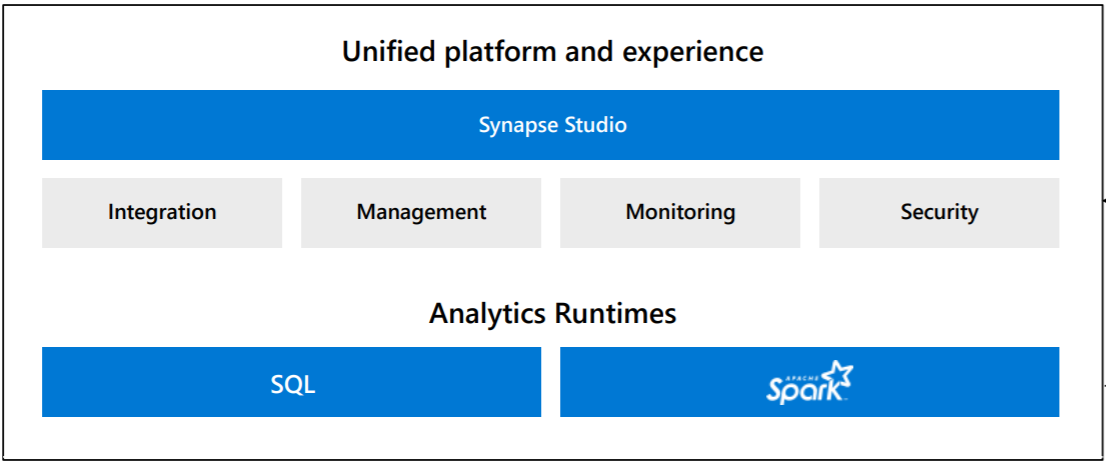
- Azure Synapse Studio : This tool is a web-based tool that provides developers to work with every aspect of Synapse Analytics from a single console. In this generally starts with creating a workspace and launching this tool that provides access to different synapse features like Ingesting data using import mechanisms or data pipelines and create data flows, explore data using notebooks, analyze data with spark jobs or SQL scripts, and finally visualize data for reporting and dashboarding purposes.
- Azure Synapse Data Integration : This service comes with an integrated orchestration engine that is identical to Azure Data Factory to create data pipelines and rich data transformation capabilities within the Synapse workspace itself. Key features include support for 90+ data sources that include Azure-based data sources, open-source and cross-cloud data warehouses and databases, file-based data sources, No SQL based data sources, etc.
-
Synapse SQL Pools : This feature of the service available in a provisioned manner where a fixed capacity of DWU units is allocated to the instance of the service for data processing. Data can be imported into Synapse using different mechanisms like SSIS, Polybase, Azure Data Factory, etc.
Synapse SQL feature is also available in a serverless manner, where no fixed capacity of the infrastructure needs to be provisioned. Instead, Azure manages the required infrastructure capacity to meet the needs of the workloads.
- Apache Spark for Azure Synapse : This component of Synapse provides Spark runtime to perform the same set of tasks like data loading, data processing, data preparation, ETLs, and other tasks that are generally related to data warehousing. Once a Synapse workspace is created, one can provision Apache Spark pools. Azure provides Data Bricks, too, as a service that is based on Spark runtime with a certain set of optimizations.
Azure Synapse Architecture
In the below diagram gives you a high level overview of what is involved in this new in workspace environment and if we look at this everything’s under a workspace an azure Synapse workspace you can create multiple workspaces. The main thing you’ll be using is azure synapse studio and this is the new product that creates that single place where everything going to be used underneath that azure synapse studio.

Ingest Layer
At the top level have Ingest data Layer into synapse studio and it’s using azure data factory. we don’t call it data factory within synapse studio but we have pipelines and data flows to ingest the data and land the data in storage.
Storage Layer
In the storage layer we have different options to load or store the data.
- Relational Database - you can land it into your traditional relational database or your data warehouse and that is what we used to call the sql data warehouse it’s the same concept it’s a relational database for your data warehouse.
- Data Lake - you can land it into your data lake store gen 2 it’s your data lake (ADLS Gen 2) or what we used to call blob store or azure data lake store and can land data in there in any type of format.
- Spark Tables - you can land it into spark table within the synapse studio. if you’re familiar with Azure Databricks. An Azure Databricks table is a collection of structured data. You can cache, filter, and perform any operations supported by Apache Spark on Azure Databricks tables. You can query tables with Spark APIs and Spark SQL.
- Cosmos db - you can land it into cosmos db within the synapse studio. Azure synapse introduced a link to cosmos db so if you land data and content on db that can be easily queried for reporting purposes.
Compute Layer
so we have ingest and we have the storage but now we have to compute on top of the storage so we have three ways of doing that in azure synapse.
-
Sql Provisioned Pool - We have the sql provision this is your traditional sql data warehouse that has a one-to-one relationship with a relational database. Dedicated SQL pool (formerly SQL DW) represents a collection of analytic resources that are provisioned when using Synapse SQL. The size of a dedicated SQL pool (formerly SQL DW) is determined by Data Warehousing Units (DWU).
When the data is ready for complex analysis, dedicated SQL pool uses PolyBase to query the big data stores. PolyBase uses standard T-SQL queries to bring the data into dedicated SQL pool (formerly SQL DW) tables.
Dedicated SQL pool (formerly SQL DW) stores data in relational tables with columnar storage. This format significantly reduces the data storage costs, and improves query performance. Once data is stored, you can run analytics at massive scale.
you can query Relational Database or Data lake you’ve created in the storage, directly from SQL pool.
-
Sql On-Demand Pool - Sql On-Demand or Serverless SQL pool is serverless, hence there’s no infrastructure to setup or clusters to maintain. A default endpoint for this service is provided within every Azure Synapse workspace, so you can start querying data as soon as the workspace is created.
There is no charge for resources reserved, you are only being charged for the data processed by queries you run, hence this model is a true pay-per-use model.
you can query Data lake, Spark table and Cosmos db you’ve created in the storage, directly from serverless SQL pool.
-
Apache Spark Pool - Azure Synapse makes it easy to create and configure a serverless Apache Spark pool in Azure.
Apache Spark includes many language features to support preparation and processing of large volumes of data so that it can be made more valuable and then consumed by other services within Azure Synapse Analytics. This is enabled through multiple languages (C#, Scala, PySpark, Spark SQL) and supplied libraries for processing and connectivity.
Spark pools in Azure Synapse are compatible with Relational Database, Azure Storage and Azure Data Lake Generation. So you can use Spark pools to process your data stored in Azure.
Visualize Layer
we have Power BI within this Azure Synapse environment and power bi now can be used in multiple different ways.
one is where call a provision pool and run a stored procedure or run a query or execute a view and it pulls data in from the relational database that could be a direct query where it pushes down the query or it can import the data into power bi.
second is where we can use power bi on top of the sql on demand pool to query data in the data lake. Suppose we have data lake store gen 2 and can run a sql on-demand pool on top of that and call that with through power BI and being charged for the data processed by queries. when that query runs through the on-demand pool through power BI so this gets me a quick way to create a report can even use power bi just to investigate the data.
Next ?
Planning to create multiple blogs episodes on azure synapse covering various areas related to azure synapse and showing you the way of using these services for implementing your data warehouse solution.
Comments