
What is Synapse Spark pool?
Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. Apache Spark in Azure Synapse Analytics is one of Microsoft implementations of Apache Spark in the cloud. Azure Synapse makes it easy to create and configure a serverless Apache Spark pool in Azure. Spark pools in Azure Synapse are compatible with Azure Storage and Azure Data Lake Storage. So you can use Spark pools to process your data stored in Azure.
Azure Synapse makes it easy to create and configure a serverless Apache Spark pool in Azure. Apache Spark includes many language features to support preparation and processing of large volumes of data so that it can be made more valuable and then consumed by other services within Azure Synapse Analytics. This is enabled through multiple languages (C#, Scala, PySpark, Spark SQL) and supplied libraries for processing and connectivity.
Once the spark pool is created it would appear in the list of spark pools in the Azure Synapse Analytics workspace dashboard page. This would mean that the spark cluster got successfully created and provisioned. Now we are ready to use this pool.
Now that the spark pool has been created, we need to test it by trying to access some sample data from Azure Data Lake Storage account.
What is Apache Spark
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching and optimized query execution for fast queries against data of any size. Simply put, Spark is a fast and general engine for large-scale data processing.
The fast part means that it’s faster than previous approaches to work with Big Data like classical MapReduce. The secret for being faster is that Spark runs on memory (RAM), and that makes the processing much faster than on disk drives.
The general part means that it can be used for multiple things like running distributed SQL, creating data pipelines, ingesting data into a database, running Machine Learning algorithms, working with graphs or data streams, and much more.
Spark Components
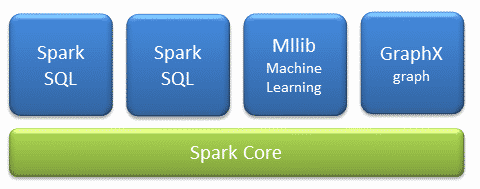
- Apache Spark Core – Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built upon. It provides in-memory computing and referencing datasets in external storage systems.
- Spark SQL – Spark SQL is Apache Spark’s module for working with structured data. The interfaces offered by Spark SQL provides Spark with more information about the structure of both the data and the computation being performed.
- Spark Streaming – This component allows Spark to process real-time streaming data. Data can be ingested from many sources like Kafka, Flume, and HDFS (Hadoop Distributed File System). Then the data can be processed using complex algorithms and pushed out to file systems, databases, and live dashboards.
- MLlib (Machine Learning Library) – Apache Spark is equipped with a rich library known as MLlib. This library contains a wide array of machine learning algorithms- classification, regression, clustering, and collaborative filtering. It also includes other tools for constructing, evaluating, and tuning ML Pipelines. All these functionalities help Spark scale out across a cluster.
- GraphX – Spark also comes with a library to manipulate graph databases and perform computations called GraphX. GraphX unifies ETL (Extract, Transform, and Load) process, exploratory analysis, and iterative graph computation within a single system.
Azure Synapse offer a fully managed Spark service.
Spark pools in Azure Synapse offer a fully managed Spark service. The benefits of creating a Spark pool in Azure Synapse Analytics are listed below.
| Feature | Description |
|---|---|
| Scalability | Apache Spark in Azure Synapse pools can have Auto-Scale enabled, so that pools scale by adding or removing nodes as needed |
| Ease to use | Synapse Analytics includes a custom notebook for interactive data processing and visualization. |
| Ease to provision | You can create a new Spark pool in Azure Synapse in minutes using the Azure portal, Azure PowerShell, or the Synapse Analytics . |
| REST APIs | Spark in Azure Synapse Analytics includes Apache Livy, a REST API-based Spark job server to remotely submit and monitor jobs. |
| Speed and efficiency | Spark instances start in minutes and also scale to number of nodes winthin an minutes |
| Support for Azure Data Lake Storage V2 | Spark pools in Azure Synapse can use Azure Data Lake Storage Generation 2 as well as BLOB storage. |
Spark pool architecture

- Spark applications run as independent sets of processes on a pool, coordinated by the SparkContext object in your main program(driver program).
- The SparkContext can connect to the cluster manager, which allocates resources across applications.
- The cluster manager is YARN. Once connected, Spark acquires executors on nodes in the pool from Resource manager, which are processes that run computations and store data for your application.
- Once the Resource manager assigned the resources it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
- The SparkContext runs the user’s main function and executes the various parallel operations on the nodes.
- The SparkContext collects the results of the operations. The nodes read and write data from and to the file system. The nodes also cache transformed data in-memory as Resilient Distributed Datasets (RDDs).
- The SparkContext connects to the Spark pool and is responsible for converting an application to a directed acyclic graph (DAG).
- The graph consists of individual tasks that get executed within an executor process on the nodes. Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads.
Apache Spark in Azure Synapse Analytics use cases
Data Engineering/Data Preparation
Apache Spark includes many language features to support preparation and processing of large volumes of data so that it can be made more valuable and then consumed by other services within Azure Synapse Analytics. This is enabled through multiple languages (C#, Scala, PySpark, Spark SQL) and supplied libraries for processing and connectivity.
Machine Learning
Apache Spark comes with MLlib, a machine learning library built on top of Spark that you can use from a Spark pool in Azure Synapse Analytics. Azure Synapse Analytics comes with built-in support for notebooks and you have an environment for creating machine learning applications.
Comments