
High Level Spark Hierarchy
A Spark application consists of a single driver process and a set of executor processes scattered across nodes on the cluster. The driver is the process that is in charge of the high-level control flow of work that needs to be done. The executor processes are responsible for executing this work, in the form of tasks, as well as for storing any data that the user chooses to cache. Both the driver and the executors typically stick around for the entire time the application is running.

-
Executor Cores/Slots : Slots indicate threads available to perform parallel work for Spark. Spark documentation often refers to these threads as cores, which is a confusing term, as the number of slots available on a particular machine does not necessarily have any relationship to the number of physical CPU cores on that machine. On Executor there are cores/slots and those slots are available to insert tasks. The driver sends tasks to the vacant slots on the executors when there is work to be executed. This ties to distributing and parallelizing an execution thread.
“Task == slot == core”
“1 Task == 1 Partition == 1 slot == 1 core”
- Executor Memory : Memory is divided into peak two types of memory primarily storage and the working memory. The working memory will be utilized for actual execution or smart workloads. The storage memory used for persistent objects. these memory can be configured, which by default is 50% so half of the memory will be allocated for working memory and half of the memory will be allocated for for storage like persisted objects.
- Local Memory : Every executor has disks. We know SPARK is an in-memory solution but we still have to have disks. The disks provide space for shuffle partitions and shuffle stages and they also provide space for persistence to disk and spills from the executor. The disks have attributes right we have fast disks we have slow disks. We have remote and local the types of disks that are attached to your cluster.
Spark Memory Management
- Spark is an in-memory processing engine spark takes data in-memory and process it.
- Allocation and usage of the memory plays a vital role in your spark application. suppose you write a good spark application but you haven’t provide and allocate the required memory to your application. The application may got delayed or failed due to OOM.
- Efficient memory use is critical for good performance because of that your application may not meet the SLA’s.
- The memory management is an important aspect for the spark application because application generates intermediate state while executing the tasks.
Memory usage is spark largely falls under the below categories:
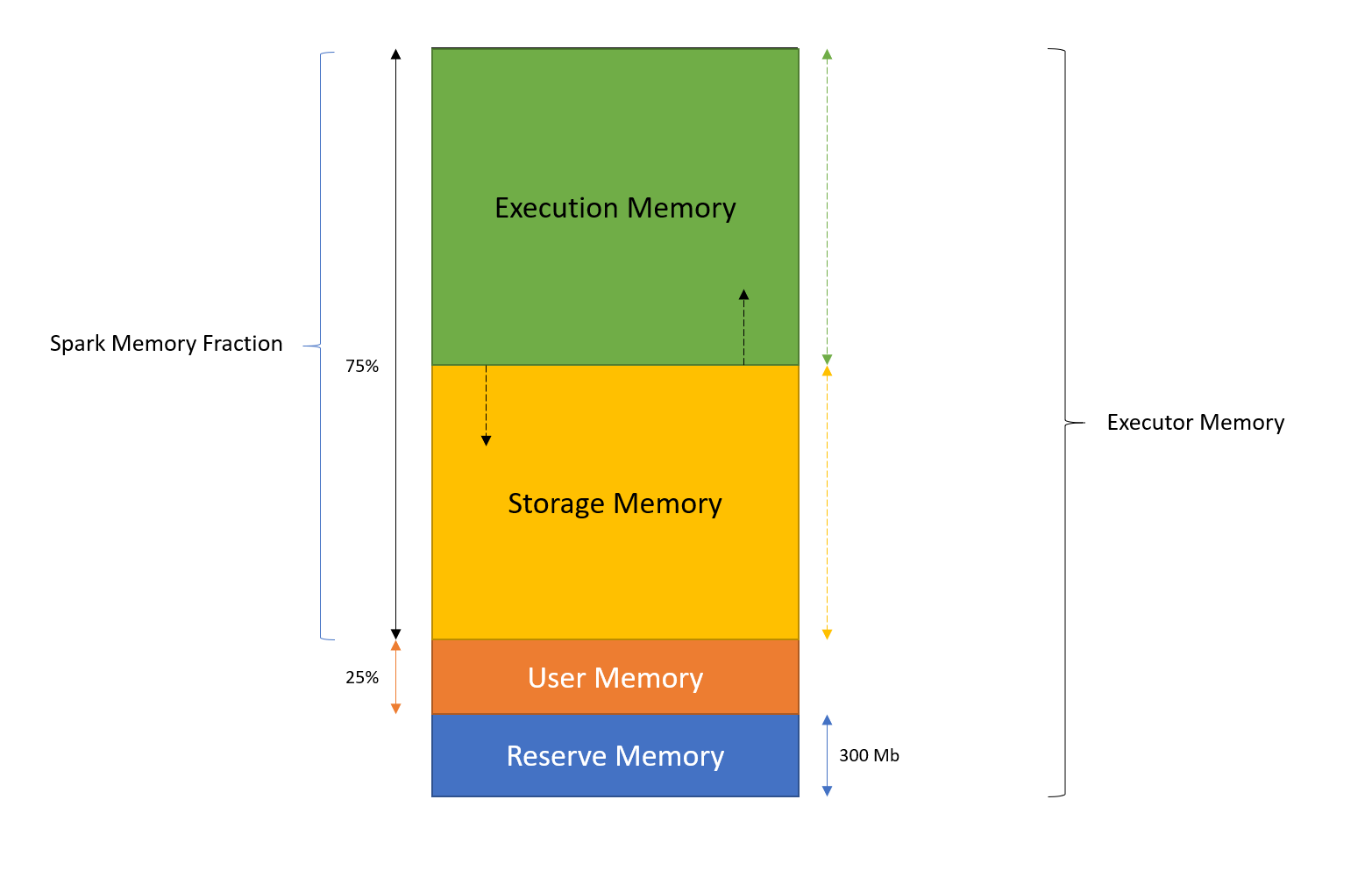
- Reserve Memory : This is the memory reserved by the system, and its size is hardcoded in the spark code. Tts value is 300MB, which means that this 300MB of RAM does not participate in Spark memory region size calculations, and its size cannot be changed in any way without Spark code recompilation or setting spark.testing.reservedMemory, which is not recommended as it is a testing parameter not intended to be used in production. Be aware, this memory is only called “reserved”, in fact it is not used by Spark in any way.
-
User Memory : This is the memory pool that remains after the allocation of Spark Memory, and it is completely up to you to use it in a way you like. You can store your own data structures there that would be used in RDD transformations. For example, you can rewrite Spark aggregation by using mapPartitions transformation maintaining hash table for this aggregation to run, which would consume so called User Memory. And again, this is the User Memory and its completely up to you what would be stored in this RAM and how, Spark makes completely no accounting on what you do there and whether you respect this boundary or not. Not respecting this boundary in your code might cause OOM error.
Calculation : (“Java Heap” – “Reserved Memory”) * (1.0 – spark.memory.fraction)
Suppose you have allocated 2GB memory then (2048 - 300) * (1.0 - 0.75) = 437 is user memory
-
Unified Memory (spark memory fraction) : This is the memory pool managed by Apache Spark. This whole pool is split into 2 regions Storage Memory and Execution Memory, and the boundary between them is set by spark.memory.storageFraction parameter, which defaults to 0.5. The advantage of this new memory management scheme is that this boundary is not static, and in case of memory pressure the boundary would be moved, i.e. one region would grow by borrowing space from another one.
Spark tasks operate in two main memory regions:
- Execution Memory : Execution memory is the memory used to the buffer intermediate results. Execution memory tends to be more short-lived than storage. It is evicted immediately after each operation, making space for the next ones. For example a task performing sort operation in that case we need some sort of collection to store the intermediate sorted value that are stored on execution memory. some other examples are shuffles results, joins, aggregation and etc.
- Storage Memory : The storage memory is more about reusing the data for future computation. Some time we need a data that i want to store in memory or disk that in future the same data i can use without re-executing the same tasks. The storage memory are for long lived memory in which cache or persist the data. suppose you have two targets and one source in your spark application which means you have called two action on same source flow in that case you can cache your data.
Important : This Unified memory doesn’t have static boundary means the memory is not fixed for execution memory and storage memory to take 50-50% memory. Spark manges this automatically if execution needs more memory then it will borrow from storage and vice versa.
Calculation : (“Java Heap” – “Reserved Memory”) * spark.memory.fraction
Suppose you have allocated 2GB memory then (2048 - 300) * 0.75 = 1311 is unified memory
Off-Heap Memory in spark
Even though the best performance is obtained when operating solely in on-heap memory, Spark also makes it possible to use off-heap storage for certain operations.
Off-heap refers to objects (serialised to byte array) that are managed by the operating system but stored outside the process heap in native memory (therefore, they are not processed by the garbage collector). Accessing this data is slightly slower than accessing the on-heap storage but still faster than reading/writing from a disk. The downside is that the user has to manually deal with managing the allocated memory.
Although most of the operations in Spark happens inside the JVM and subsequently uses the JVM Heap for its memory, each executor has the ability to utilize an off-heap space for certain cases. This off-heap space lies outside the JVM space and is generally accessed via sun.misc.Unsafe APIs. The off-heap memory is outside the ambit of Garbage Collection, hence it provides more fine-grained control over the memory for the application developer.
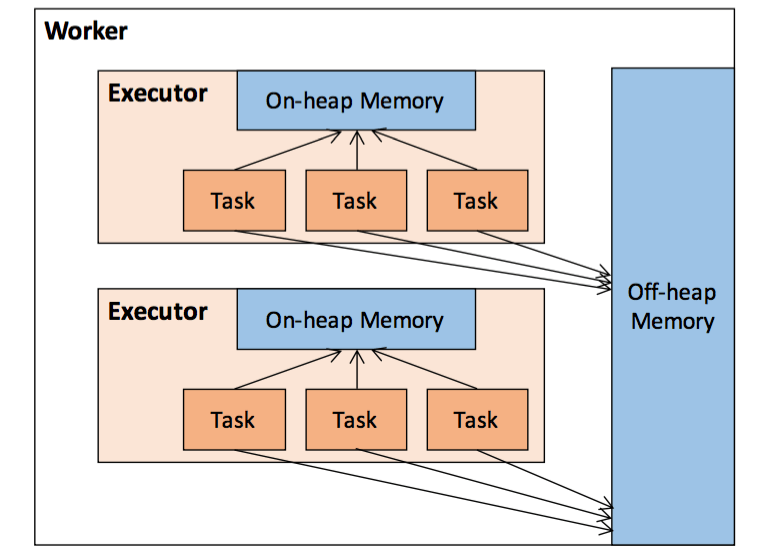
The total off-heap memory for a Spark executor is controlled by spark.yarn.executor.memoryOverhead. The default value for this is 10% of executor memory subject to a minimum of 384MB. This means, even if the user does not explicitly set this parameter, Spark would set aside 10% of executor memory(or 384MB whichever is higher) for VM overheads. The amount of off-heap memory used by Spark to store actual data frames is governed by spark.memory.offHeap.size. This is an optional feature, which can be enabled by setting spark.memory.offHeap.use to true.
- spark.memory.offHeap.enabled – the option to use off-heap memory for certain operations (default false)
- spark.memory.offHeap.size – the total amount of memory in bytes for off-heap allocation. It has no impact on heap memory usage, so make sure not to exceed your executor’s total limits (default 0)
Calculations for Spark Memory
Consider:
10 Node Cluster ( 1 Master Node, 9 Worker Nodes)
Each 16VCores and 64GB RAM
-
spark.executor.cores Balanced approach is 5 virtual cores for each executor is ideal to achieve optimal results in any sized cluster. (Recommended)
Parameter : –executor-cores = 5
-
spark.executor.instances we have total 16 cores and 1 core is reserved for hadoop and we calculated number of cores are 5. Calculation : (16 -1) / 5 => 3 which means we can run 3 instances of executors per node.
we have total 9 worker nodes. Calculation : (3 * 9) -1 => 26 which means we can spawn upto 26 executors.
Parameter : –num-executors = 26
-
spark.executor.memory we have total 64 GB RAM and 1 GB is reserved for Hadoop. We have calculated 3 instances of executor per node. Calculation :(63 / 3) => 21 which means we can give upto 21 GB memory per executor.
This total executor memory includes both heap memory and off heap in the ratio of 90% and 10%.
spark.executor.memory = 21 * 0.90 = 19GB
spark.yarn.executor.memoryOverhead = 21 * 0.10 = 2GB
Parameter : –executor-memory = 19GB
Next ?
Planning to create multiple blogs episodes on Spark Performance Tuning. Covering the various areas of spark where we can improve the pipeline/job.
Comments