
What is Data Skew?
Data skew is not an issue with Spark, rather it is a data problem. The cause of the data skew problem is the uneven distribution of the underlying data.
Data skew happens when a small percentage of partitions get most of the data being processed. In normal usage, Spark will generally make sure that the data is evenly split across all tasks, so there isn’t a big risk of skew. When you do a join or aggregation, Spark distributes the data by key, so that data the same keys goes to the same Node or task. If you have a lot of rows with the same key, then you have some tasks with those keys taking much longer than the others.
For Example :
Suppose we have four partitions of data as below and when they come in at 128 MB each they are roughly the same size in terms of number of records and number of MBs. However, once we perform a group by city, the first 3 cities are roughly uniform but the last city is significantly larger than other cities which results in a data skewness (uneven distribution of records in partitions)
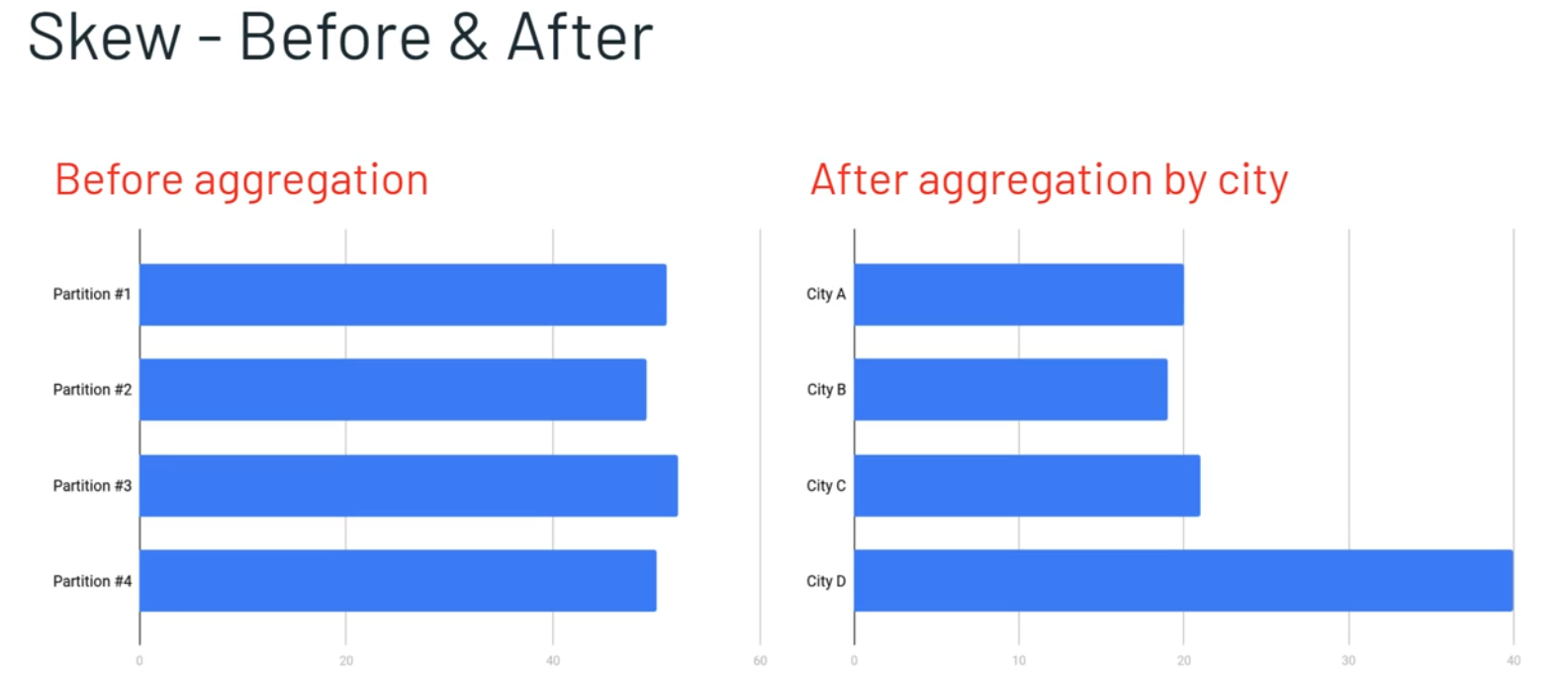
- The skewed partition/task (City D) will take more time as compared to other cities.
- The skewed task take more memory as compared to other cities.
- The single skewed task will impact the whole stage or job. because spark execute 4 partitions/task simultaneously and wait to complete the whole stage.
challenge :
Let’s assume one task is taking the maximum amount of data like 70-80 percent to the entire data.
- In that situation you actually don’t get any benefit if you increase the number of partitions/tasks. because one of the task taking most of the data.
- In that situation if you take larger machines in terms of resources memory and CPU cores but still not get any benefit because one of the task taking more memory.
Handling Skewness in spark
1. Repartitioning
In spark we have partition types called input, output and shuffle. The input and output partition size are controlled by the partition size of the input data but the shuffle partition is based on the count so naturally and unfortunately we have to do little math to figure out.
1) Input Partition Sizing : For input partition spark generally do a great job of taking care of these input partitions(Spark Defaults input partition size is 128MB) but sometimes it doesn’t work properly and there’s a lot of reasons.
Increase Parallelism Sometimes we need to increase the parallelism of the job. for example let’s say I have a big cluster having 100 CPU cores. but I only have 100 megabytes of data for processing. In spark we have 128 megabytes input partition size which will wind up to generate only two partitions. The spark will take only two cores out of 100 cores.
In that case we can down the partition size to one megabyte(Property to change the partition size spark.sql.files.maxPartitionBytes) so that we can utilize the whole cluster CPU cores.
spark.conf.set(“spark.sql.files.maxPartitionBytes”,”16777216”) -> 16MB
2) Output Partition Sizing : The output partition can be used either for change the size of the files or you want to change the composition of the files. To change the size of the files you have a couple different ways either coalesced or repartition.
val spark = SparkSession
...
val df=spark.read.csv("path")
...
// you can pass in any interger value to increase the partition
df.coalesce(1)
df.repartition(1)
// you can pass multiple columns to increase the partition
df.repartition(col("pk"))
3) Shuffle Partition Sizing : The default for a shuffle is changed by a count and it’s controlled with the flag. The default count is 200. We need to change the count according to the use case e.g. if you have 200 partitions and you have more than 20 GB of data this is the wrong number.
Basic formula to calculate the shuffle count :

2. Use of Combiner
A Combiner, also known as a semi-reducer, is an optional class that operates by accepting the inputs from the Map class and thereafter passing the output key-value pairs to the Reducer class. The main function of a Combiner is to summarize the map output records with the same key.
The groupByKey call makes no attempt at merging/combining values, so it’s an expensive operation. Thus the combineByKey call is just such an optimization. When using combineByKey values are merged into one value at each partition then each partition value is merged into a single value.
- If there are many records of the same key then repartition does not help you out then combiner will be a good option.
- Combiner decrease the size of the shuffle data and reduces the load during aggregation phase.
Important : No matters if your data is skewed or not always good to have combiner.
3. Salting
Salting with Two-Phase aggregation
Fixing the data skew problem required salting the data sets — meaning adding randomization to the data to allow it to be distributed more evenly. It also required two-stages of aggregation.
- Salting is adding some random prefix or suffix in the original key.
- Let’s assume we have a skewed key called
StockBrandFoowith the randomness of 10 integers, we can create keys like StockBrandFoo_0, StockBrandFoo_1 … StockBrandFoo_9 here _0,_1 are the salts. - Once we created the salted key then we can use in aggregation and key can get spread across multiple nodes due to salting.
- Next we can do the Two-Phase aggregation. In the first phase we can do the aggregation(we can say partial aggregation) on salted keys. In the second phase we can remove the salt and do the final aggregation on the original keys.
val spark = SparkSession
...
val sch = StructType(List(
StructField("pk", DataTypes.StringType),
StructField("sales", DataTypes.IntegerType)
))
val df=spark.read.schema(sch).csv("path")
val addSalt=df.withColumn("salted_pk", concat(col("pk") , lit("_"), floor(rand()*100)))
val firstPhase=addSalt.groupBy("salted_pk").agg(sum("sales").as("sum_sales"))
val removeSalt=firstPhase.withColumn("pk", substring_index(col("salted_pk"),"_",1))
val secondPhase=removeSalt.groupBy("pk").sum("sum_sales")
Salting with Two-Phase aggregation only for skewed fields
Fixing the data skew problem required salting the data sets. If we already know the skewed keys then we can add salting(randomization to the data to allow it to be distributed more evenly) and do two-stages of aggregation. for the rest of the fields we can do direct aggregation and after that union whole the data.
- Instead of salting all the keys, construct two Data frames one with non skewed keys and one with skewed keys..
- Perform two-phase aggregation only for the slated keys and for non skewed keys perform direct aggregation and merge the results.
val spark = SparkSession
...
val sch = StructType(List(
StructField("pk", DataTypes.StringType),
StructField("sales", DataTypes.IntegerType)
))
val df=spark.read.schema(sch).csv("in.txt")
val skewedKeys=df.filter(col("pk") === "p2")
val nonSkewedKeys=df.filter(col("pk") =!= "p2")
val addSalt=skewedKeys.withColumn("salted_pk", concat(col("pk") , lit("_"),floor(rand()*100)))
val firstPhase=addSalt.groupBy("salted_pk").agg(sum("sales").as("sum_sales"))
val removeSalt=firstPhase.withColumn("pk", substring_index(col("salted_pk"),"_",1))
val secondPhase=removeSalt.groupBy("pk").agg(sum("sum_sales").as("sumOfSales"))
val nonSkewedSum=nonSkewedKeys.groupBy("pk").agg(sum("sales").as("sumOfSales"))
val merged=nonSkewedSum.union(secondPhase)
Salting while Joining
Fixing the data skew problem required salting the data sets. Suppose we have two data frames and one with large data and skewed on particular key. second data frame is medium in size but we can’t fit in-memory or perform broadcast join.
- For Large data frame we can add salting in the particular join key within a range and distribute the keys more evenly.
- For second data frame we need to explode the values within the same range of first data frame.
val spark = SparkSession
...
val sch = StructType(List(
StructField("pk", DataTypes.StringType),
StructField("sales", DataTypes.IntegerType)
))
val df=spark.read.schema(sch).csv("in.txt")
val df2=spark.read.schema(sch).csv("in2.txt")
val skewedDF1=df.withColumn("salt_pk", concat(col("pk") , lit("_"),floor(rand()*3)))
val skewedDF2=df2.withColumn("salt_pk", explode(array( (0 to 3).map(lit(_)): _*)))
skewedDF1.join(skewedDF2,skewedDF1("salt_pk") === concat(skewedDF2("pk"),lit("_"),skewedDF2("salt_pk")) ).drop("salt_pk")
4. MapSide Join
To handle skewness in join one option is perform mapside Join. but the constraint is in advance we know the skewed keys and skewed data will be fit in memory for mapside join.
- We need to filter out the skewed keys from both the data frames which will be joined later and create separate skewed and non skewed data frames .
- On skewed data frames, broadcast both the skewed data frames which having skewed keys and perform the mapside join
- On non skewed data frames, we can simple perform the hash join on non skewed data.
- Last we can merge the results of both the joins.
val spark = SparkSession
...
val sch = StructType(List(
StructField("pk", DataTypes.StringType),
StructField("sales", DataTypes.IntegerType)
))
val df=spark.read.schema(sch).csv("path1")
val df2=spark.read.schema(sch).csv("path2")
val skewedDataDF1=df.filter(col("pk")==="p2")
val skewedDataDF2=df2.filter(col("pk")==="p2")
val mapSideJoin=broadcast(skewedDataDF1).join(broadcast(skewedDataDF2),df("pk")===df2("pk"),"inner")
val nonSkewedDataDF1=df.filter(col("pk")=!="p2")
val nonSkewedDataDF2=df2.filter(col("pk")=!="p2")
val hashJoin=nonSkewedDataDF1.join(nonSkewedDataDF2,df("pk")===df2("pk"),"inner")
mapSideJoin.union(hashJoin).show()
Next ?
Planning to create multiple blogs episodes on Spark Performance Tuning. Covering the various areas of spark where we can improve the pipeline/job.
Comments