
Need of File Format
A file format is the definition of how information is stored in HDFS. Hadoop does not have a default file format and the choice of a format depends on its use case. File format should be well-defined and expressive. It should be able to handle variety of data structures specifically structs, records, maps, arrays along with strings, numbers etc.
The big problem in the performance of applications that use HDFS such as Spark is the time it takes to find relevant data in a particular location and the time it takes to write the data back to another location. Managing the processing and storage of large volumes of information is complex, in addition to other difficulties such as the evolution of storage schemes or restrictions. Along with the storage cost, processing the data comes with CPU, Network, IO costs, etc., As the data increases, the cost for processing and storage increases too.
Benefits of choosing an appropriate file format:
- Faster read times
- Faster write times
- Splittable files
- Schema evolution support
- Advanced compression support
Different types of file formats
Some file formats are designed for general use, others are designed for more specific use cases, and some are designed with specific data characteristics in mind. So there really is quite a lot of user choice.
- Unstructured : The text files like CSV, TSV are mostly unstructured because text files are raw data and may contain more and less fields. But text files are also come under structured data as well.
- Semi-Structured : The semi structured data may contains different fields per row and different kinds of fields. Semi structured data that contains tags or markers as an semantic elements, but they aren’t as rigid as structured data. Typical examples of semi-structured data are XML and JSON.
- Structured : Structured data formats, rigidly enforce schema and data type rules. Many leverages this knowledge about the data to provide optimizations at query time right out of the box. Typical examples of structured data are Apache Avro, Apache ORC and Apache Parquet.
Physical Layout of file formats
1. Row oriented Storage
Row oriented databases are databases that organize data by record, keeping all of the data associated with a record next to each other in memory. A row wise stored methodology, rows are stored contiguously on disk. The data stored one after another inside of block. This type of storage methodology can be great if your goal is to access full rows at a time.
In a row store, or row oriented database, the data is stored row by row, such that the first column of a row will be next to the last column of the previous row. This allows the database write a row quickly because, all that needs to be done to write to it is to tack on another row to the end of the data.
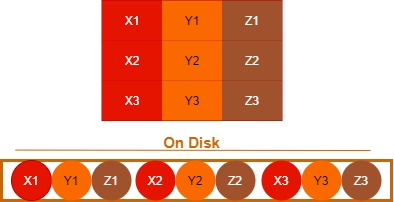
Challenges in Row Oriented Storage:
- if you want to read data from third row of data, A2, B2, C2 is a pretty trivial operation in the row oriented model.
- if you want to reconstruct the second column then this would require a linear scan of the entire data set.
- if you want to update the second column values then this model would read the whole data that we don’t require for the operation.
- if you want to do aggregation then it brings extra data (columns) into memory which is slower than only selecting the columns that you are performing the aggregation on it.
2. Column oriented Storage
In a C-Store, columnar, or Column-oriented database, the data is stored column wise such that each row of a column will be next to other rows from that same column. In the columnar storage methodology, columns are stored contiguously On-disk. These types of Storage are read optimized.
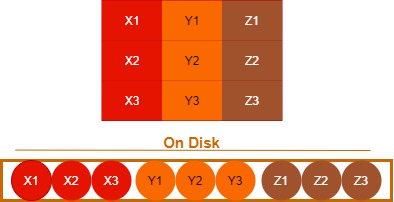
Challenges in Row Oriented Storage:
- if you want to add a new row then it become the fairly intensive process.
- if you have a workflow which requires heavy write then this model become a lot more expensive.
- Most of the column wise models are not ACID compliance.
3. Hybrid Storage
The hybrid storage model is a combination of both the row-wise and the columnar-wise model. In this model, we first select the groups of rows that we intend to store. In this model we create row groups and we will apply the columnar layout inside each of the row groups. In this we’ve logically grouped together the rows of the table with the help of columnar partitioning scheme inside of the group.

Types of Workflows
OLTP(Online Transaction Processing Workflow)
An OLTP system captures and maintains transaction data. Each transaction involves individual data records made up of multiple fields or columns. Examples include banking and credit card activity or retail checkout scanning. In OLTP, the emphasis is on fast processing, because OLTP databases are read, written, and updated frequently. If a transaction fails, built-in system logic ensures data integrity.
- It operates with short lived transactions or queries.
- More processing focused rather than analysis focused.
- It focused towards row based processing rather than column based processing.
- In this data is generally updated and deleted on a per record basis or transaction basis.
- It is Normalized workflow for efficiency.
OLAP(Online Analytical Processing Workflow)
OLAP applies complex queries to large amounts of historical data, aggregated from OLTP databases and other sources, for data mining, analytics, and business intelligence projects. In OLAP, the emphasis is on response time to these complex queries. Each query involves one or more columns of data aggregated from many rows.
- These are generally workflows that involve column based analytics.
- It operates with the more complex queries.
- These types of workflows are best stored by columnar storage formats.
- Handles large volumes of data with complex queries
Let’s examine the different file formats
1. CSV
It is a Row-based format and CSV files (comma-separated values) are usually used to exchange tabular data between systems using plain text. CSV is a row-based file format, which means that each row of the file is a row in the table. Essentially, CSV contains a header row that contains column names for the data, otherwise, files are considered partially structured. CSV files may not initially contain hierarchical or relational data. Data connections are usually established using multiple CSV files. Foreign keys are stored in columns of one or more files, but connections between these files are not expressed by the format itself.
- Flexible
- Row-based
- Human Readable
- Compressible
- Splittable
- Fast write
2. JSON
It is a Row-based format and JSON (JavaScript object notation) data are presented as key-value pairs in a partially structured format. JSON is often compared to XML because it can store data in a hierarchical format. Both formats are user-readable, but JSON documents are typically much smaller than XML.
- Self describing schema
- Row-based
- Compressible
- Splittable
- Supports complex type
- Supports hierarchical structures
3. Avro
It is a Row-based format that has a high degree of splitting. It is also described as a data serialization system similar to Java Serialization. The schema is stored in JSON format, while the data is stored in binary format, which minimizes file size and maximizes efficiency. Avro has reliable support for schema evolution by managing added, missing, and changed fields. Since Avro is a row-based format, it is the preferred format for handling large amounts of records as it is easy to add new rows.
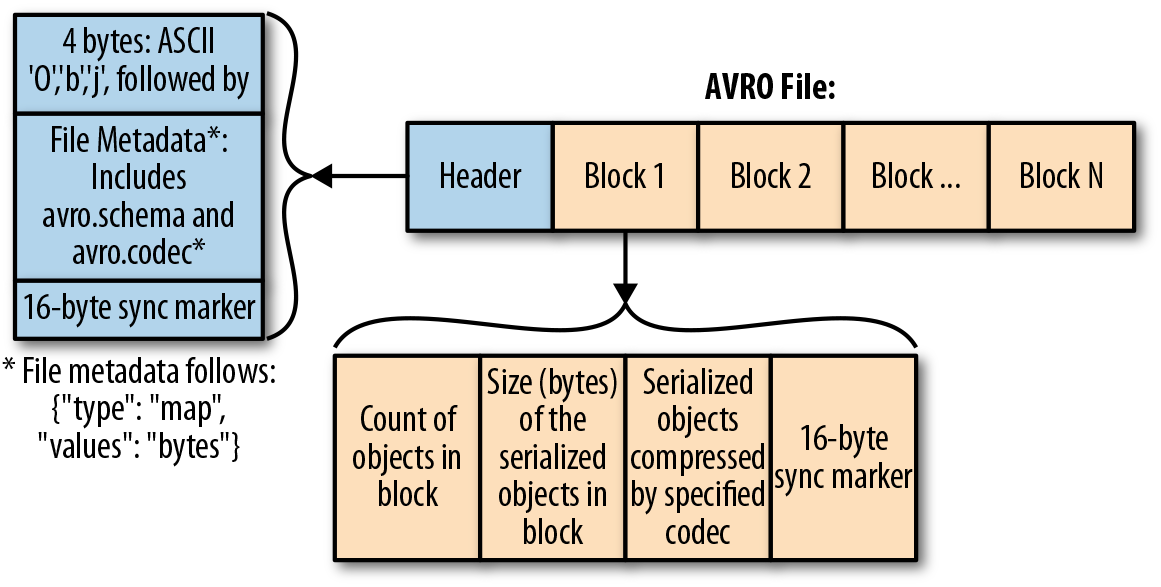
- Data format and Data Serialization
- Schema stored in a file header
- Row-based
- binary format
- Compressible
- Splittable
- Supports complex type
4. ORC
It is a Hybrid based format and ORC(Optimized Row Columnar) file format provides a highly efficient way to store data. It was designed to overcome the limitations of other file formats. It ideally stores data compact and enables skipping over irrelevant parts without the need for large, complex, or manually maintained indices.

ORC file working :
- ORC stores collections of rows in one file and within the collection the row data is stored in a columnar format.
- An ORC file contains groups of row data called stripes, along with auxiliary information in a file footer. At the end of the file a postscript holds compression parameters and the size of the compressed footer.
- The default stripe size is 250 MB. Large stripe sizes enable large, efficient reads from HDFS.
- The file footer contains a list of stripes in the file, the number of rows per stripe, and each column’s data type. It also contains column-level aggregates count, min, max, and sum.
Stripe footer contains a directory of stream locations. Row data is used in table scans. Index data include min and max values for each column and the row’s positions within each column. ORC indexes are used only for the selection of stripes and row groups and not for answering queries. Postscript contains compression parameters and the size of the compressed footer.
5. Parquet
It is a Hybrid based format and Parquet is optimized for the paradigm Write Once Read Many (WORM). It writes slowly but reads incredibly quickly, especially when you only access a subset of columns. Parquet is good choice for heavy workloads when reading portions of data. For cases where you need to work with whole rows of data, you should use a format like CSV or AVRO. Parquet files are binary files that contain metadata about their contents. Therefore, without reading/parsing the contents of the file(s), metadata is used to determine column names, compression/encoding, data types, and even some basic statistical characteristics. Column metadata for a Parquet file is stored at the end of the file, which allows for fast, single-pass writing.
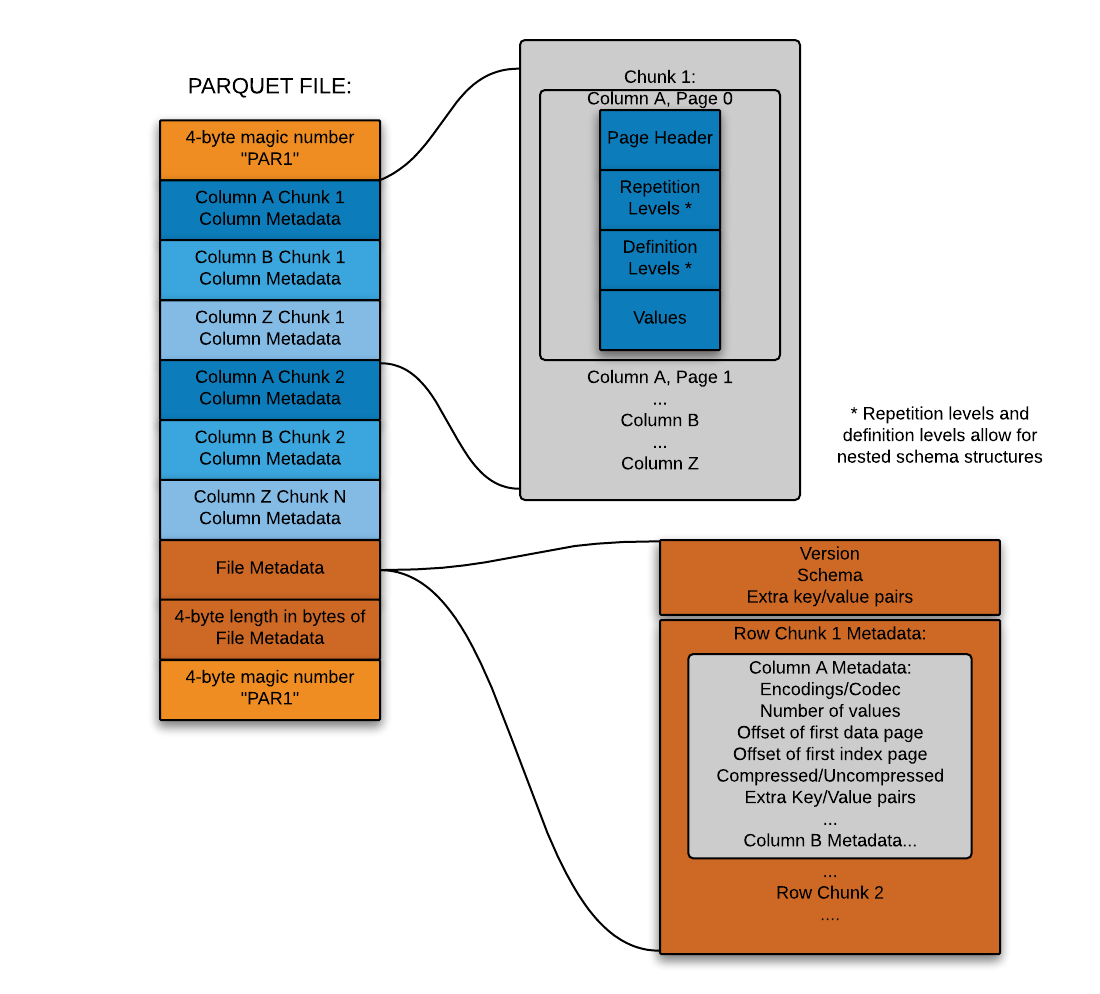
- Row group: A logical horizontal partitioning of the data into rows. A row group consists of a column chunk for each column in the dataset.
- Column chunk: A chunk of the data for a particular column. These column chunks live in a particular row group and are guaranteed to be contiguous in the file.
- Page: Column chunks are divided up into pages written back to back. The pages share a common header and readers can skip the page they are not interested in.
Footer contains the following
- File metadata- The file metadata contains the locations of all the column metadata start locations. Readers are expected to first read the file metadata to find all the column chunks they are interested in. The column chunks should then be read sequentially. It also includes the format version, the schema, and any extra key-value pairs.
- length of file metadata (4-byte)
- magic number “PAR1” (4-byte)
Predicate Pushdown / Filter Pushdown
The basic idea of predicate pushdown is that certain parts of queries (predicates) can be “pushed” to where the data is stored. For example, when we give some filtering criteria, the data storage tries to filter out the records at the time of reading. The advantage of predicate pushdown is that there are fewer disk i/o operations and therefore overall performance is better. Otherwise, all data will be written to memory, and then filtering will have to be performed, resulting in higher memory requirements.
This optimization can significantly reduce the request/processing time by filtering the data earlier than later. Depending on the processing framework, the predicate pushdown may optimize the query by performing such actions as filtering data before it is transferred over the network, filtering data before it is loaded into memory, or skipping reading entire files or pieces of files.
When reading data from the data storage, only those columns that are required will be read, not all fields will be read. Typically, column formats such as Parquets follow this concept, resulting in better I/O performance.
Final Words
Think about the organizations workload and see the workflow needs OLTP or OLAP. which further you can decide the file format according to the workflow(Row, Columnar or Hybrid). File format selection can have a large performance gain. Organizations workflow can decide the file format so that better results can be gathered.
Next ?
Planning to create multiple blogs episodes on Spark Performance Tuning. Covering the various areas of spark where we can improve the pipeline/job.
Comments