
The Evolution of file formats
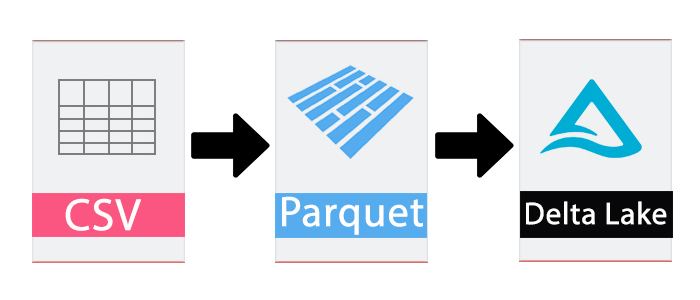
- when people started storing files at that time they just had CSV files and they took some straight data to data lake. The problem with CSV was csv doesn’t know the structure of the file means how many columns in it and second compression in csv doesn’t really help.
- Then Parquet format come into existence and solve couple of CSV problems. The parquet file format is columnar storage it store the data in columns wise and that means we can compress it really well. It has a structure so don’t need to mentioned separately just read the data. Parquet also has some drawbacks like ACID transactions, versioning, handling metadata and etc.
- Then Delta Lake come into the picture to solve all of the problems. The Delta lake is a file format the same as csv and parquet except it’s kind of a wrapper means the data lives in parquet format inside it and it gives us a transaction log and many more features around the top.
What is Delta Lake?
In the past there are different storage solutions build to solve the common problem of data quality. Many architecture/tools are build to solve the problem. These tools provides many benefits like decoupling the business logic from storage and compute. It means user can scale the compute and storage power up and down but in between this data reliability lost. To provide the data reliability and quality Delta Lake come into the picture.
Delta Lake is a file-based, open-source storage format that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. It runs on top of your existing data lakes and is compatible with Apache Spark and other processing engines. Delta Lake combine the both worlds OLAP(Online Analytical Processing) and OLTP(Online Transactional Processing) with the horizontal scalability of data lakes.
- ACID transactions : It is really important that the data integrity is maintained in data lake means no more partial or corrupted data. Delta Lake ensures that all data changes written to storage are committed for durability and made visible to readers atomically.
- Unified Batch and Stream Processing : In a Data lake, if we have an use case of both Stream processing and Batch processing it is normal to follow Lamdba architecture. But Delta Lake table has the ability to work both in batch and as a streaming source and sink all just work out of the box.
- Scalable data and metadata handling : Delta Lake is built on data lakes, all reads and writes using Spark or other distributed processing engines are inherently scalable to petabyte-scale. Delta Lake leverages Spark to scale out all the metadata processing to handle metadata or large tables.
- Time Travel : The Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes. Data in the data lake will be versioned and snapshots are provided so that you can query them as if that snapshot was the current state of the system. This helps us to revert to older versions of our data lake for Audits, rollbacks and etc.
- Schema Enforcement : Delta Lake automatically prevents the insertion of data with an incorrect schema, i.e. not matching the table schema. It prevents data corruption by preventing the bad data get into the system.
- Support for updates, merge and deletes : Delta Lake supports merge, delete , and update operations to do complex operations. Most of the distributed processing frameworks do not support atomic data modification operations on data lakes.
How to start with Delta Lake
- Databricks Community Edition : The Databricks Community Edition is the free version of our cloud-based big data platform. Users can access a micro-cluster as well as a cluster manager and notebook environment. You can start with the Databricks environment in which the delta lake packages are pre-installed.
- Set up project : If you want to build a project using Delta Lake binaries from Maven Central Repository, you can use the following Maven coordinates.
<dependency> <groupId>io.delta</groupId> <artifactId>delta-core_2.12</artifactId> <version>1.0.0</version> </dependency>def writeToDelta(spark: SparkSession,path:String): Unit ={ val df = spark.range(10) df.write.format("delta").save(path) } def readFromDelta(spark: SparkSession,path:String): Unit ={ spark.read.format("delta").load(path).show() } def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .master("local") .getOrCreate() //Write to delta table writeToDelta(spark,"/delta_path") //Read from delta table readFromDelta(spark,"/delta_path") }Creating your first Delta Table
While creating a Delta table you have to provide the location, which means you are writing files to some storage. All of the files together stored in a directory of a particular structure which make up your table. Which means when we create a Delta table, we are in fact writing files to some storage location.
-
Writing to Delta Table : In the below code example, we will first create the Spark Data Frame and then use the write method to save the delta table to storage location.
//Write the Spark DataFrame to Delta table val df = spark.range(10) df.write.format("delta").save("/delta_store") // Write the Spark DataFrame to Delta table partitioned by date val added_date = df.withColumn("date",current_date()) added_date.write.partitionBy("date").format("delta").save("/delta_store") // Append new data to your Delta table df.write.format("delta").mode(SaveMode.Append).save("/delta_store") // Overwrite your Delta table df.write.format("delta").mode(SaveMode.Overwrite).save("/delta_store") - Reading from Delta Table : Like writing your Delta table, you can use the DataFrame API to read the same files from your Delta table.
// Read the data from the Delta table location spark.read.format("delta").load("/delta_store").show()%sql SELECT * FROM delta.`/delta_store` -
Create Delta table in metastore : we can save the Delta table files into a location managed by the metastore (e.g. /user/warehouse/myTable). If you want to use SQL or control the location of your Delta table.
// Write the data to the metastore defined table as delta_table val df = spark.range(10) df.write.format("delta").saveAsTable("delta_table")%sql select * from delta_table - Create Delta table using SQL : user can create the delta table by sql and load the data by sql commands.
%sql -- Create a table in the metastore CREATE TABLE delta_table ( id INTEGER) USING DELTA LOCATION "/delta_store"// Create temp table of the DataFrame val df = spark.range(10) df.createOrReplaceTempView("tmp_view")%sql CREATE TABLE delta_table USING DELTA LOCATION "/delta_store" AS SELECT * FROM tmp_view;
What files are kept under the Delta table location
In Delta table creation the LOCATION property that points to the underlying files. These files and folder makes the Delta table special.
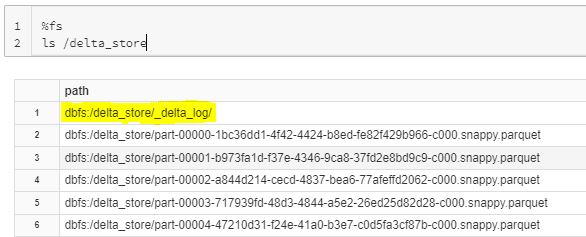
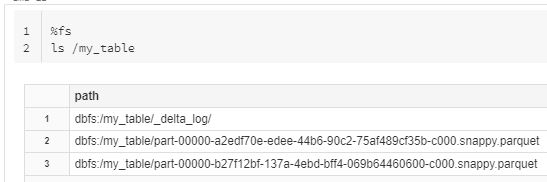
If we see in the above results of ls command we have bunch of output files in parquet (that we will discuss later) and one directory called _delta_log. As we know Delta lake provides number of features like ACID transactions, scalable metadata handling, time travel and others. The Delta lake have achieved these functionalities with the help of _delta_log also known as Delta transaction log.
How Delta table physically store ?

- Suppose you have a table called my_table underneath table contain the above shown directory structure on disk.
- In in table root directory we have the transaction log directory, which is called _delta_log.
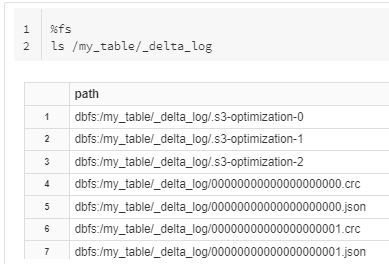
- Within the _delta_log directory we have multiple versions of json files. These are numbered zero to long max value. these files contain all the transactions or changes that you make to your Delta table.
- Next we have optional partition directory. if your Delta table is partitioned on some particular column then it will create the directory accordingly like above we have a partition on year column it will create directories year wise.
- If your table is partitioned then underneath the partition directory it will create the data files which are simple parquet files. And if the table is not partitioned then the data files will create under the table root directory in parquet format.
What is Transaction Log or Delta Log?
The Delta Lake transaction log (also known as the Delta Log) is an ordered record of every change that has been performed on a Delta Lake table.
- Delta Lake is built on top of Apache Spark so that at the same time multiple readers and writers work on the table.
- It shows the correct view of the table all times, means due to transaction log feature table will always in updated state.
- The Delta Lake transaction log serves the single source of truth like a central repository that tracks all changes that users make to the table.
- No partial or corrupted files because delta lake either the commit the state or abort the state. which means if job fails in between there will be no entry in the transaction log.
Lets understand by code
Lets create one delta table with some dummy data. below is the query to create and load the dummy data.
%sql
DROP TABLE IF EXISTS my_table;
CREATE TABLE my_table
USING DELTA
LOCATION "/my_table"
AS SELECT 'dummy1' as f1, 'dummy2' as f2 ;
After the table is created and loaded with dummy data. we can see in the below diagram having one _delta_log directory and another one is data file in parquet format.
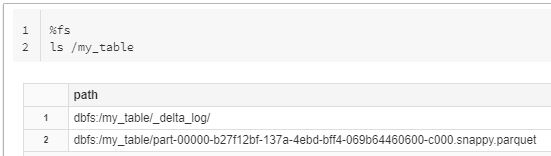
If we check under the _delta_log directory we can see bunch of files but the only 0000000.json file (later we see the .json file) is used by delta lake to maintain the history and versions.
Lets run the insert query on the same table and add some more dummy data to the table.
%sql
insert into my_table values ('dummy2','dummy2')
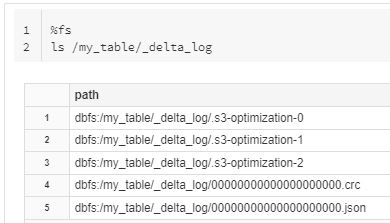
Once the values are inserted into the table. we can see in the below diagram we have the same _delta_log directory and one more data file is created in parquet format.
If we again check under the _delta_log directory we can see some common files and one more file is created with 0000001.json (later we see the .json file). This file is used by delta lake to maintain the history and versions.
Great! In this blog we learn the basic of delta lake like setup a project and basic commands. In next blog we will deep dive into Transaction Log in delta lake. See you in the next blog.
Comments