
How Transaction Log Works ?
A Delta Lake table is a directory on file system that holds data files with the table contents and a log of transaction operations. The Delta Lake’s approach is to store a transaction log and metadata directly on file system no need to maintain separate service for metadata and log handling.
The transaction log is stored in the _delta_log subdirectory within the table. It contains a sequence of JSON objects with increasing numerical IDs. It also contain occasional checkpoints for specific log objects that summarize the log up to that point in Parquet format.
LogStore Implementation
In Delta lake generate the transaction log files and they must exist somewhere like some storage systems to store the files. Delta Lake ACID guarantees the atomicity and durability of the storage system. Delta lake relies on the following when interacting with storage systems.
- Atomic visibility : Any file written through this store must be made visible, atomically means be visible entirely or not visible at all.
- Mutual exclusion : Only one writer must be able to create a file at the final destination.
- Consistent listing : Once a file has been written in a directory, it should offers ACID consistent listing of files.
Because storage systems do not necessarily provide all of these guarantees out-of-the-box. For that Delta Lake used the Log store API to provide the ACID guarantees for different storage systems, user can use different LogStore implementations.
The LogStore, similar to Apache Spark, uses Hadoop FileSystem API to perform reads and writes. So Delta Lake supports concurrent reads on any storage system that provides an implementation of FileSystem API.
Action performed on each transaction
Each log record object contains an array of actions. Whenever a user performs an action like INSERT, DELETE, UPDATE or MERGE the Delta Lake breaks that operation down into series of below steps :
- Update metadata : The metadata action changes the current metadata of the table. The metadata is a data structure containing the schema, partition column names and other configuration options, such as marking a table as append-only.
- Add file : The add actions is used to add the file path into the log data structure. The add record for a data object can also include data statistics, such as the total record count and per-column min/max values and null counts.
- Remove file : The remove actions is used to remove the file path from the log data structure. The remove action includes a timestamp that indicates when the removal occurred. Physical deletion of the data object can happen lazily after a user-specified retention time threshold.
- Set transaction : To record own data inside log records, which can be useful for implementing end-to-end transactional application like structured streaming job has committed a micro-batch with the given ID and store appId and version fields in txn action.
- Change protocol : The protocol action is used to increase the version of the Delta protocol that is required to read or write a given table.
- Commit info : The commit info data structure contains the information of user commit means which operation was made, where, what time and etc.
Let’s read the first transaction log of version 0 and explore the schema
spark.read.json("delta_load_table/_delta_log/00000000000000000000.json").printSchema()
root
|-- add: struct (nullable = true)
| |-- dataChange: boolean (nullable = true)
| |-- modificationTime: long (nullable = true)
| |-- path: string (nullable = true)
| |-- size: long (nullable = true)
| |-- stats: string (nullable = true)
|-- commitInfo: struct (nullable = true)
| |-- clusterId: string (nullable = true)
| |-- isBlindAppend: boolean (nullable = true)
| |-- isolationLevel: string (nullable = true)
| |-- notebook: struct (nullable = true)
| | |-- notebookId: string (nullable = true)
| |-- operation: string (nullable = true)
| |-- operationParameters: struct (nullable = true)
| | |-- description: string (nullable = true)
| | |-- isManaged: string (nullable = true)
| | |-- partitionBy: string (nullable = true)
| | |-- properties: string (nullable = true)
| |-- timestamp: long (nullable = true)
| |-- userId: string (nullable = true)
| |-- userName: string (nullable = true)
|-- metaData: struct (nullable = true)
| |-- createdTime: long (nullable = true)
| |-- format: struct (nullable = true)
| | |-- provider: string (nullable = true)
| |-- id: string (nullable = true)
| |-- partitionColumns: array (nullable = true)
| | |-- element: string (containsNull = true)
| |-- schemaString: string (nullable = true)
|-- protocol: struct (nullable = true)
| |-- minReaderVersion: long (nullable = true)
| |-- minWriterVersion: long (nullable = true)
ACID Transaction with Delta Lake
Delta Lake provides transaction logs. The transaction log is a collection of ordered json files acts as a single source of truth. By using transaction log it always give the latest version of a DeltaTable state.
- Atomicity : Delta Lake breaks down every action performed by a user into atomic commits. Successful completion of all actions ensures that transaction log record that commit, means A commit is recorded in the transaction log once the action is completed successfully and ensuring its atomicity.
- Consistency : Delta Lake provides strong schema checking for DeltaTable . So the consistency of a DeltaTable is guaranteed by their strong schema.
- Isolation : Delta Lake takes care of Concurrency of commits is managed to ensure their isolation. This is done using optimistic concurrency control.
- Durability : Delta Lake made all the transactions on Delta Lake tables and stored directly to disk as successfully completion make them durable.
Concurrency Control
How does Delta Lake deal with multiple concurrent reads and writes. Because Delta Lake is runs on Apache Spark, means that multiple users concurrently modify a single table. Delta Lake provides ACID transaction guarantees between reads and writes.
- Readers continue to see the consistent snapshot view of the table that the Spark job started with, even when the table is modified during the job.
- Multiple writers can simultaneously modify a table and see a consistent snapshot view of the table and there will be a serial order for these writes.
Optimistic concurrency control
Delta Lake uses optimistic concurrency control to provide transactional guarantees between writes. Under this mechanism, writes operate in three stages:
- Read: Reads (if needed) the latest available version of the table to identify which files need to be modified (that is, rewritten).
- Write: Stages all the changes by writing new data files.
- Validate and commit: Before committing the changes, checks whether the proposed changes conflict with any other changes that may have been concurrently committed since the snapshot that was read. If there are no conflicts, all the staged changes are committed as a new versioned snapshot, and the write operation succeeds. However, if there are conflicts, the write operation fails with a concurrent modification exception rather than corrupting the table as would happen with open source Spark.
How to recomputing the state with Checkpointing.
Checkpoint is just an optimization technique that allows to quickly access metadata as Parquet file without need to scan individual transaction log files.
- Checkpoint writes a checkpoint of the current state of the delta table (Snapshot). That produces a checkpoint metadata with the version. Checkpoint requests the LogStore to overwrite the _last_checkpoint file with the JSON-encoded checkpoint metadata.
- Checkpoints store all the non-redundant actions in the table’s log up to a certain log record ID, in Parquet format. Some sets of actions are redundant and can be removed.
- The result of the checkpointing process is an Parquet file that contains an add record for each object still in the table, remove records for objects that were deleted but need to be retained until the retention period has expired, other records such as txn, protocol and changeMetadata.
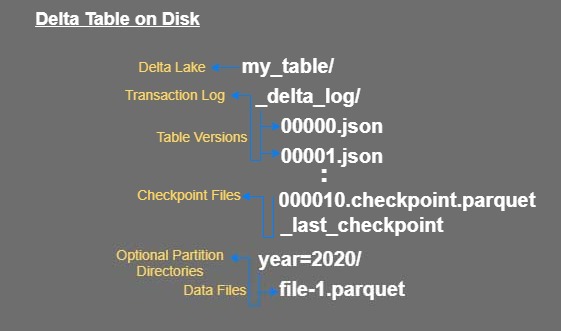
Let’s understand by example:
In small scale application which has limited transactions on that scenario reading from the small set of transaction log files (JSON format) is easy. But in large scale applications like streaming applications which creates multiple small files (due to micro batching) the problem where it become inefficient to read the whole bunch of transaction log files (JSON format) to know the state of the DeltaTable.
- The delta lake solve the problem with checkpointing. Delta Lake creates a checkpoint file in Parquet format after it creates the 10th commits. This parquet file is easy for spark to read and compute the state.
- When recompute the state of the DeltaTable, Spark will read and cache the available JSON files that make up the transaction log. For example, if there have been only four commits to the table Spark will read all four files and cache the results into memory (like cache version 4).
- The clients accessing the Delta Lake table they just need to find the last checkpoint without Listing all the objects in the _delta_log directory.
- Suppose in DeltaTable have 11 commits then next spark will directly read from the last checkpoint file instead of going back to version 0 (read all the log files to compute the state).
- Checkpoint writers write their new checkpoint ID in the _delta_log/_last_checkpoint file this ID will be used to create next checkpointing file.
Great! In this blog we learn how Transaction Log works and delta lake maintain the table state in the form of log files. In next blog we will deep dive into other features of delta lake. See you in the next blog.
Comments