
Problem
Data engineering pipeline often go wrong when dirty/bad data ingested from the external sources. After that it is hard to undo the changes or updates in the data lake. In addition to that there are aspects like data auditing and understand how the data is changed over the time.
Solution
Delta lake cater the problem and provide a solution to go back in time and solve the above challenges. Delta automatically versions the big data that you store in your data lake. When we write our data into a Delta table, every operation is automatically versioned and we can access any version of data. Delta lake provide a data management like functionality in which you do easy audit, roll back of bad data and reproduce the data.
Lets first create a Delta table
-
Initial Load
val source_path = "/FileStore/tables/testData/part_00000_67f679a1_1d91_4571_9d54_54ab84497267_c000_snappy.parquet" val target_path ="/FileStore/tables/deltaTimeTravel" spark.read.parquet(source_path).write.format("delta").save(target_path) spark.read.format("delta").load(target_path)display( spark.read.json("/FileStore/tables/deltaTimeTravel/_delta_log/00000000000000000000.json") .select("add.path") .where("add is not null") )The below results shows the files which are added during the initial load in the transaction log (Query
select("add.path").where("add is not null")))
- Append Data
import org.apache.spark.sql.functions._ spark.range(5) .withColumn("state",lit("N/A")) .withColumn("count",lit(2)) .select("state","count") .write.format("delta").mode("append").save(target_path)display( spark.read.json("/FileStore/tables/deltaTimeTravel/_delta_log/00000000000000000001.json") .select("add.path") .where("add is not null") )In the append mode sample files are added by the Spark range function. The below results shows the files in the transaction log (Query
select("add.path").where("add is not null")))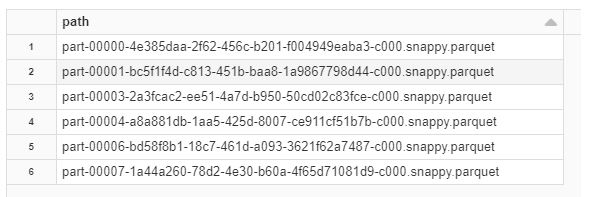
-
Delete Data
import io.delta.tables.DeltaTable DeltaTable.forPath("/FileStore/tables/deltaTimeTravel").delete("count == 2")display( spark.read.json("/FileStore/tables/deltaTimeTravel/_delta_log/00000000000000000002.json") .select("remove.path") .where("remove is not null") )For the delete query we used DeltaTable API for simple delete (it will not physically remove the files, it just marked as deleted in transaction log metadata) the data from the Detla table. The below results shows the deleted files in the transaction log (Query
select("remove.path").where("removeis not null")))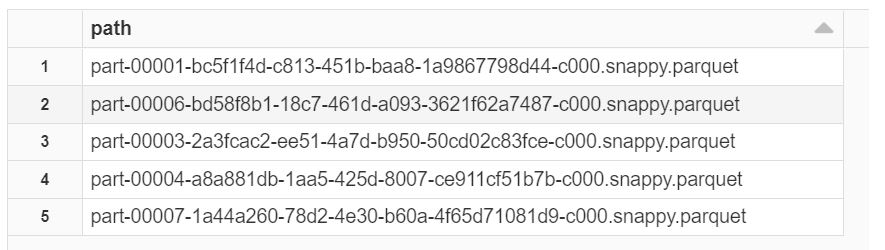
Working with Time Travel using 2 approaches
Every Operation in Delta table is automatically versioned and we can access any version of data. This allows to travel back to a different version of the delta table. Lets first see the history of the Delta table.
import io.delta.tables.DeltaTable
display(DeltaTable.forPath("/FileStore/tables/deltaTimeTravel").history())

1. Using with Timestamp
You can provide the timestamp or date string as an option to the DataFrame reader. User can see the history and select the appropriated version of the Delta table.
-
First version of Delta table (Initial load)
spark.read.format("delta") .option("timestampAsOf","2021-07-02T10:26:40.000+0000") .load(target_path).count() res29: Long = 52 -
Second version of Delta table (Append)
spark.read.format("delta") .option("timestampAsOf","2021-07-02T10:52:52.000+0000") .load(target_path).count() res29: Long = 57 -
Third version of Delta table (Delete)
spark.read.format("delta") .option("timestampAsOf","2021-07-02T11:34:35.000+0000") .load(target_path).count() res29: Long = 52
2. Using with Version Number
You can provide the version number string as an option to the DataFrame reader. User can see the history and select the appropriated version of the Delta table.
-
First version of Delta table (Initial load)
spark.read.format("delta") .option("versionAsOf","0") .load(target_path).count() res29: Long = 52 -
Second version of Delta table (Append)
spark.read.format("delta") .option("versionAsOf","1") .load(target_path).count() res29: Long = 57 -
Third version of Delta table (Delete)
spark.read.format("delta") .option("versionAsOf","2") .load(target_path).count() res29: Long = 52
Time Travel Use Cases
- Governance and Auditing : Time Travel offers data quality, standards and metrics by governance. It also offers auditing of records of every change made to a Delta table. It also offers Optimization, Retention and vacuum of data.
- Debug : By using time travel user can easily debug the data issues. Like troubleshoot the ETL pipeline issues, data quality issues which breaks the data pipeline. By using time travel user can explore all versions of Delta table and find out which version causing the issue.
- Rollbacks : Time travel also makes it easy to do rollbacks. In case of bad data enters into the data lake using external sources. User can easily rollback to a previous version of the Delta table and fix the issue.
- Reproduce reports & experiments : Time travel also helps to reproduce the experiments. suppose the source data added or modified by upstream pipelines without knowing anyone. These data changes create struggle for data scientist to reproduce their experiments. by using time travel data scientist can reproduce the experiments by different versions.
Comments