
Problem
Data lakes holds large amount of data, and periodically data will change due to updates, merge and deletes on data lake. With the traditional data lakes(on big data) it difficult to perform such a simple operations (because no one supports ACID). So that the user need to build there own strategy to perform these operations but in this approach data consistency is big threat, and it can become very difficult for data engineering and data scientists to reason about their data.
Solution
Delta Lake solves this issue by enabling data analysts to easily query all the data in their data lake using SQL. Then, data engineering or data scientists can perform update, merge or delete on the data using SQL or programmatically, because to Delta Lake supports ACID transactions.
What is DML Operation
DML refers to “Data Manipulation Language”, a subset of SQL statements which deals with data manipulation. A transaction is a sequence of one or more SQL statements that can SELECT, INSERT, UPDATE, DELETE the data.
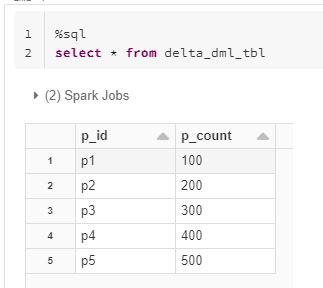
Lets first create a Delta table
dbutils.fs.rm("/FileStore/tables/deltaDML",true)
val source_path = "/FileStore/tables/data/test_data_snappy.parquet"
val target_path ="/FileStore/tables/deltaDML"
spark.read.parquet(source_path).write.format("delta").save(target_path)
spark.read.format("delta").load(target_path).createOrReplaceTempView("delta_dml_tbl")
Delta Lake : UPDATE
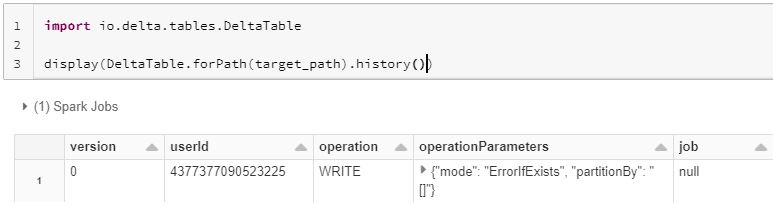
You can use the UPDATE operation to selectively update any rows that match a filtering condition, also known as a predicate. An SQL UPDATE statement changes the data of one or more records in a table. Either all the rows can be updated, or a subset may be chosen using a condition.
Update by SQL query
UPDATE delta_dml_tbl SET p_count = "550" WHERE p_id = 'p5'
Update by Scala programmatically
import io.delta.tables.DeltaTable
val dt = DeltaTable.forPath(target_path)
dt.updateExpr("p_id == 'p5'",Map("p_count"->"550"))
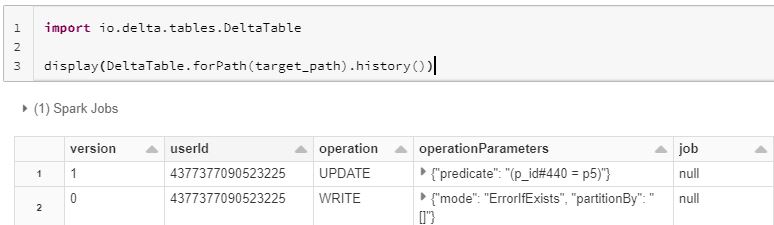
how update works internally
Delta Lake maintains files under the hood. As above created delta table has version 0 of the table where it have four files. Now, lets say you run Update. What it will do underneath is that it will use two scans on this data, to update detla table.
- First Scan :
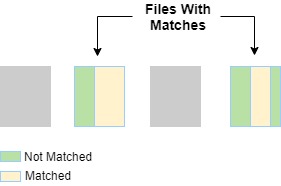
- First it will do a scan the files that contains the data that needs to be updated based on the predicate.
- let’s say out of four files, two of the files has data that matches the predicate. Delta stores the data as parquet files.
- So now not all the rows in the parquet files may match the data, so there will be some rows that matches the predicate, some rows that does not match the predicate,
- Delta Lake uses data skipping, Z-order, Bloom filter whenever possible to speed up this process.
- As you can see labels green and yellow in the above diagram. Now to identify these files, it uses the predicate, column stats and partition pruning to narrow down the search space.
-
Second Scan :
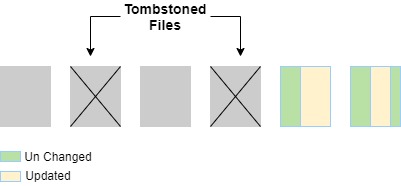
- Now once we find out the files, it selects them and does one more scan on the selected files
- So in the second scan two files are re-written as completely new files. because we can’t change in the existing parquet files and re-write those files.
- The data in the files that matched actually got updated. And the data that not matched got just copied into these new files.
- And the files that got replaced (old matched files) are tombstoned, which means we add the information that two new files got added and replaced files will remove in the transaction log.
Delta Lake : DELETE
You can use the DELETE operation to selectively delete rows based upon a predicate. The DELETE command is used to delete existing records from a table either it can be single record or multiple records depending on the condition.
Delete by SQL query
DELETE FROM delta_dml_tbl WHERE p_id = 'p5'
Delete by Scala programmatically
import io.delta.tables.DeltaTable
val dt = DeltaTable.forPath(target_path)
dt.delete("p_id == 'p5'")
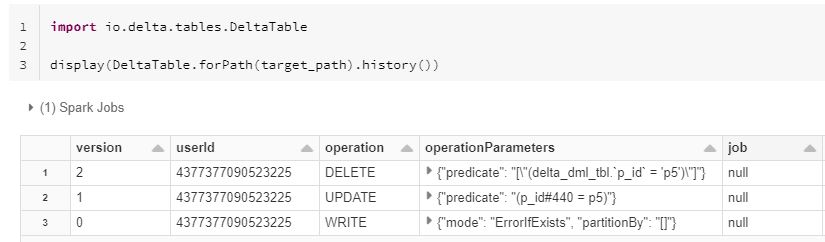
how update works internally
The Delete works same as Update internally, Delete makes a two scans for search and delete. The first scan find out the data files that match the data with respect to predicate. The second scan read the matching files and write the new files which does not contain the rows with matched the predicate.
Cleaning up old data files
The old files are not deleted once the delete operation completed. These files marked as “tombstoned” (no longer part of the active table) in the Delta Lake transaction log. If you want to delete the old “tombstoned” files you can use the VACUUM command.
- no longer part of the active table, and
- older than the retention threshold, which is seven days by default.
VACUUM command
import io.delta.tables.DeltaTable
val dt = DeltaTable.forPath(target_path)
// retention period, which is 168 hours (7 days) by default
dt.vacuum()
// user can change the retention period to 72 hours.
dt.vacuum(72)
Delta Lake : MERGE
In Delta Lake the MERGE operation allow user to perform upserts. how merge works is it will update the existing records and insert the new records to delta table.
- When a record from the source table matches a record in the target table, Delta Lake UPDATE the record.
- When there is no match, Delta Lake INSERTS the new record.
Merge by SQL query
MERGE INTO delta_dml_tbl
USING delta_dml_tbl_src
ON delta_dml_tbl_src.p_id = delta_dml_tbl.p_id
WHEN MATCHED THEN UPDATE
SET delta_dml_tbl.p_count = delta_dml_tbl_src.p_count
WHEN NOT MATCHED THEN
INSERT (p_id, p_count) VALUES (p_id, p_count)
Merge by Scala programmatically
import io.delta.tables.DeltaTable
val dt = DeltaTable.forPath(target_path)
dt.alias("t")
.merge(src.alias("s"),"t.p_id = s.p_id")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()

how update works internally
What happens internally is exact same thing as Update/Delete, there are two scans of the data, one to find the list of match files that needs to be updated, and a second scan to update those files by re-writing them as new files. But in merge needs join between the source and the target to actually find the matches.
- In the first scan is the inner join between the target and source. The inner join find out all the matched files.
- The second scan is an outer join between only the selected files in target and the source and write out the updated/deleted/inserted data, and even some of the data may be copied, some of the data may be updated, deleted, inserted.
Comments